9주차. Ensemble methods - Gradient Boosting Machine : GBM
서울시립대학교 인공지능학과 노영민 교수님의 데이터 마이닝 강의를 정리함을 미리 알립니다.
https://dogunkim.tistory.com/24
위 글에서 Adaboost에 대해 소개했다. 이걸 공부하고 넘어오자.
- Gradient Boosting Machine : GBM
정리. Adaboost vs GBM
Weak model의 단점을 해결하기 위해 Adaboost는 잘못 분류된 데이터 포인트에 대해 높은 가중치를 주며 해결하였다.
하지만 GBM은 Weak model의 단점을 해결하기 위해 gradients를 이용하여 해결한다.
즉 Boosting하는 것은 같지만.. 어떤 방법으로 weak model의 단점을 해결하는가는 다른 것이다.
아래 선형 회귀 예시를 확인하며 GBM에 대해 이해해보자.

학습 결과 모델 $f_1$ 선형 모델이 나왔다. 이 때 다음 학습 과정(Round2) 에서는 에러 y - $f_1$를 새로운 target으로 잡고 학습을 진행한다.
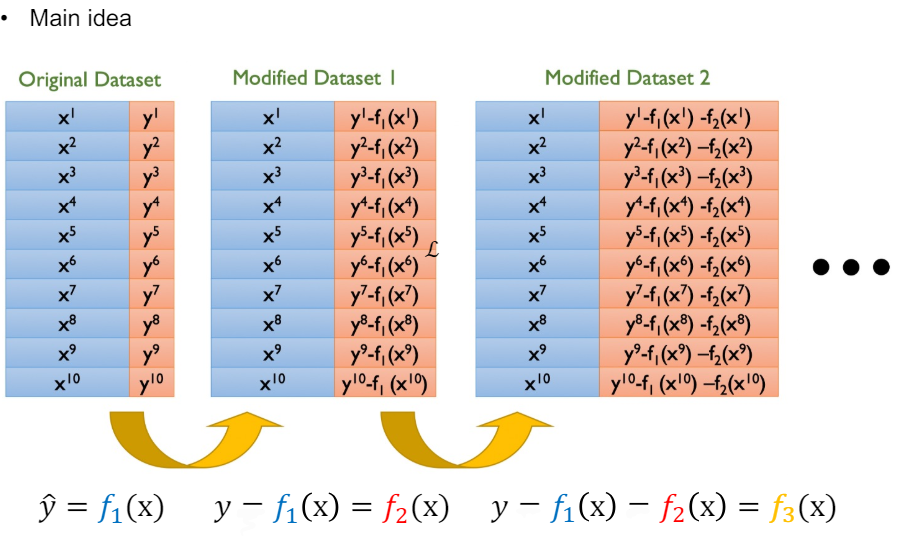

그래 다음 Round에서 Regisual을 새로운 target으로 잡고 해당 Round의 weak 모델을 학습시키는 것을 이해했다.
하지만 왜 이게 gradient와 연관이 있다는 걸까?
다음과 같은 Loss function을 잡고 모델 자체에 대해 편미분을 하면 Risidual과 음의 gradient가 같음을 보일 수 있다. ***

<Example>

해당 데이터를 통해 GBM을 학습시켜보겠다.
(Round 1)
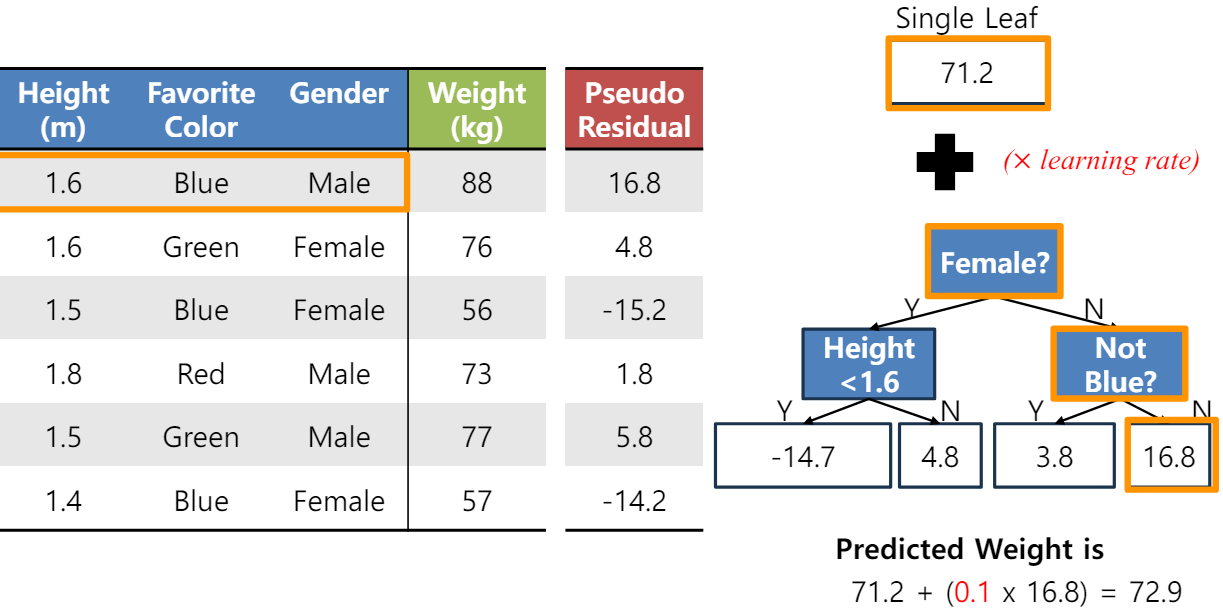
1) Residual를 설정하기 위해 기존 target의 평균인 single leaf를 둔다. 이 Single leaf는 데이터 데이터 분류 자체를 안하기에 stump tree보다 약한 모델이다. #Single leaf는 residual을 정의하기 위한 초기 예측이지, Round1의 weak model 아니다.

2) Single leaf를 토대로 Residual를 정의한다.

3) 이제 이 Residual를 Target으로 하는 Weak model를 찾는다.
모든 경우의 수를 다 볼 수 없으므로 다음과 같은 model이 찾아졌다 가정한다.

4) 분류된 target를 평균화한다.

이제 이렇게 학습된 모델로 데이터를 예측할 수 있다. 1열 data point가 들어오면 single leaf의 값과 Round1의 weak model의 분류된 값으로 값을 알 수 있다.

5) 각 Round의 weak model의 가중치를 설정한다. ***시험 2개
weak model에 가중치가 없다면 Overfitting의 가능성이 존재하고, Residual이 0에 가까울 수 있다.
Overfitting을 방지하고, Residual를 만들기 위해 모델에 가중치 Learning rate를 준다.

(Round2)
1) Round2의 weak model이 target으로 할 잔차를 결정한다. 이 잔차를 계산할 때 앙상블 기법이 사용된다.
# Learning rate를 조심하자.


2) 해당 잔차를 target으로 하는 새로운 weak model를 결정한다.
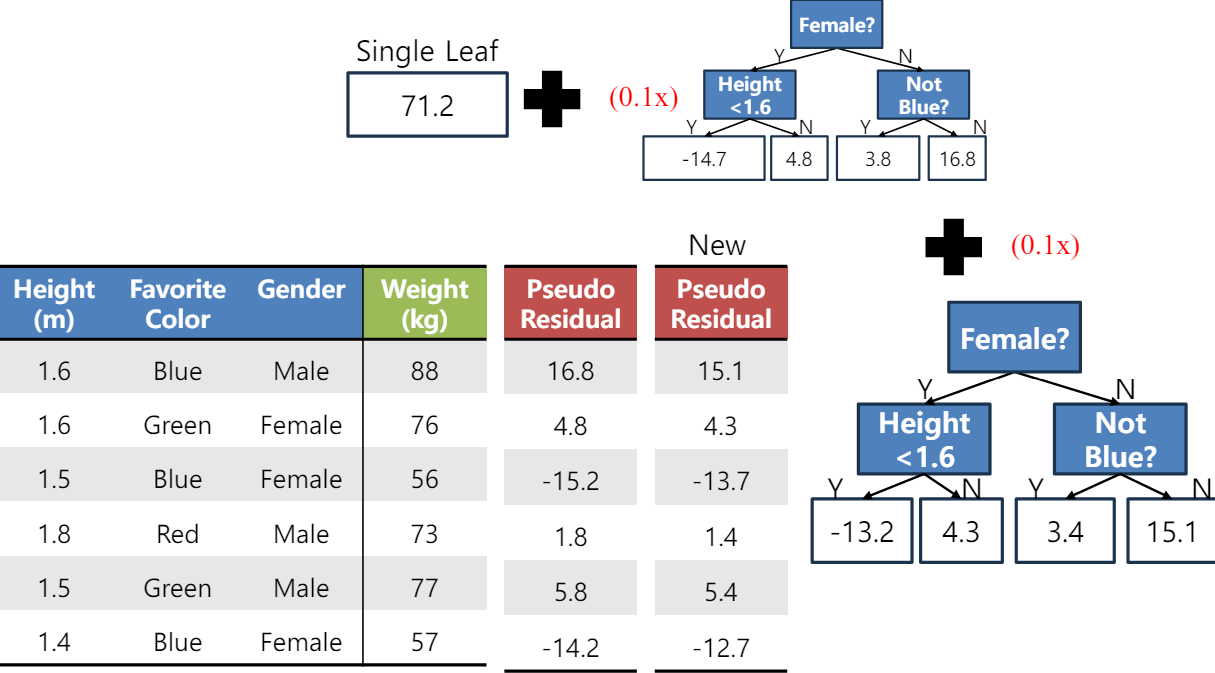
3) 모델이 결정 되었으면 앞 모델들은 일단 무시하고, 새로 계산된 잔차에 대해 학습하고 평균 내어 분류한다.
이를 반복한다.
이 때 모델은 Residual이 가장 빨리 줄어드는 모델을 선택한다. 우리는 residual = - gradient를 0으로 보내며 Loss function을 최소화 하는 방향으로 모델을 학습하고 있다. (Gradient Descent 느낌..!)
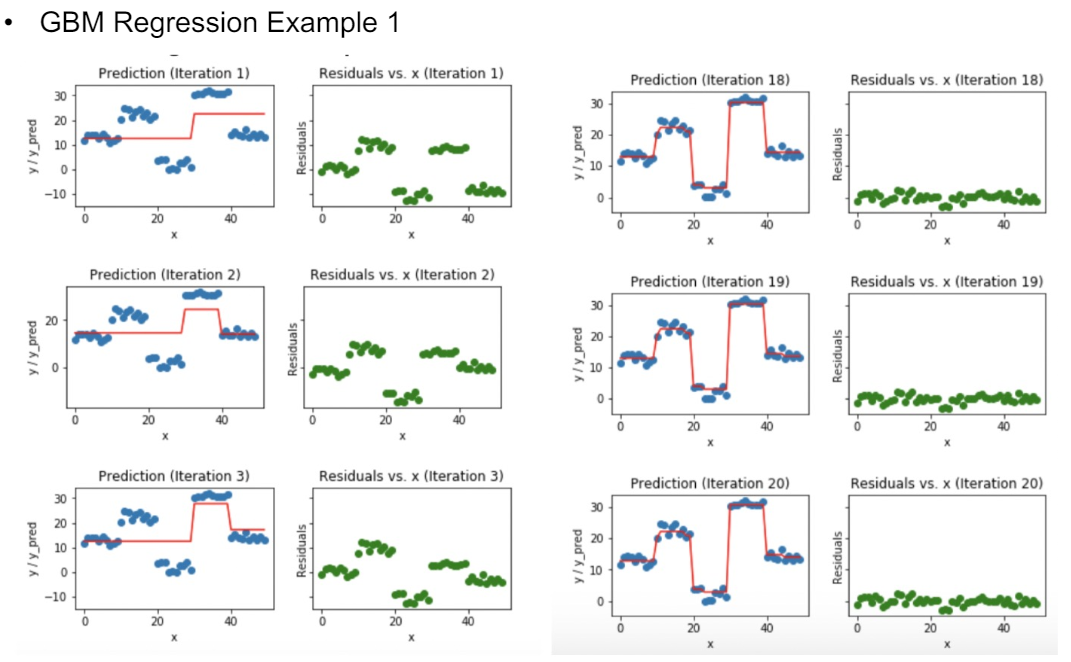
반복하며 Residual이 0으로 수렴하고 있다. 즉 loss function의 gradient가 0으로 수렴한 것이다. 이 때 최적해를 보일 것이다..


- GBM Loss function ***암기
맨 처음에 주어진 Loss 함수만 있는게 아니다. 다음과 같은 함수 또한 사용 가능하다.
1) Regression을 위한 Loss function 4가지.

2) Classfication을 위한 Loss function 2가지.

- GBM의 단점 ***예상 문제 Q. GBM의 단점을 설명하고 이를 해결하기 위한 방법을 서술하라.
GBM은 Overfitting이 잘 일어난다는 단점이 존재한다. 이를 해결하기 위한 3가지 방법을 공부할 것이다.
1) Subsampling
정규화 방법 중 하나인 Subsampling은 각 라운드의 weak model를 학습하기 위한 훈련 데이터를 랜덤하게 일부분만 추출하여 훈련에 사용하는 방법이다. 예를 들어 100개의 훈련 데이터가 있다면 각 라운드에 랜덤한 80개의 훈련 데이터를 주고 훈련 시키는 것이다. 일반적으로 비복원 추출로 진행되지만, bagging 방식도 사용될 수 있다.
2) Shrinkage Learning rate
정규화 방법 중 하나인 Shrinkage Learning rate는 각 라운드의 weak model의 영향을 줄이는데 사용된다. 적은 학습률을 사용하면 모델이 더 천천히 신중하게 학습되며 overfitting을 방지하고 일반화 성능을 높히는데 도움이 된다.
3) Early stopping
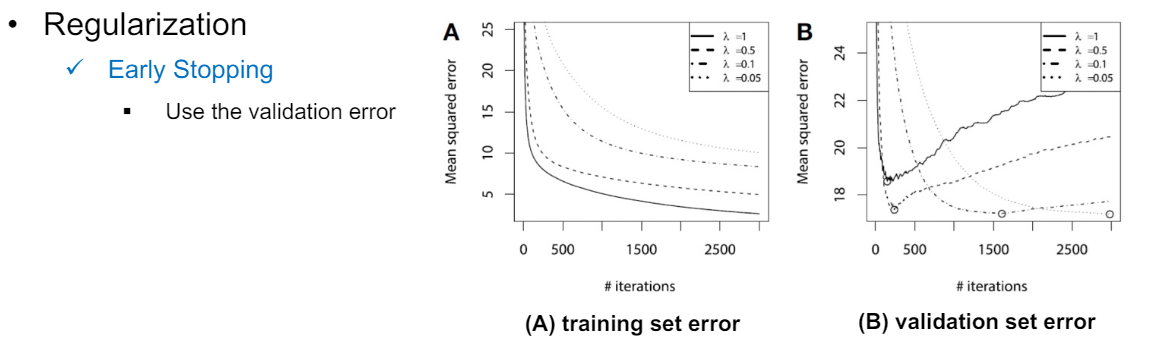
vaildatuon set error가 최소일 때, 학습을 그만둔다. 그림으로 보는게 쉽다. 훈련 데이터에 대해서는 훈련을 반복하면 과적합되면서 error가 계속 감소하겠지만, vaildation set에 대해서는 error가 증가할 것이다. 학습을 적당한 선에서 빠르게 그만둔다.
- Variable Importance in Tree-based Gradient Boosting ****예상 문제 # Information Gain 이용 * 식 암기

cf) Adaboost에서 weak model를 결정하기 위해서 가중 평균 Gini index를 사용했다.
GBM에서 weak model은 gradient가 0으로 빠르게 수렴하는 모델 = residual이 빨리 감소하는 모델을 선택한다.
GBM에서 변수 중요도를 구할 수 있었는데 모든 모델에 대해 각 변수의 Information Gain을 계산하고 평균 내면 됐다.

'학부 수업 > 데이터마이닝' 카테고리의 다른 글
| 09. Ensemble methods - Boosting: AdaBoost (0) | 2024.06.19 |
|---|---|
| 8. Support Vector Machine with Kernel Trick (1) | 2024.06.19 |
| 8. Support Vector Machine with Soft Margin (3) | 2024.06.19 |
| 7. Support Vector Machine with hard-margin (2) | 2024.06.17 |
| 6. Random Forest (3) | 2024.05.20 |