서울시립대학교 인공지능학과 노영민 교수님의 데이터 마이닝 강의를 정리함을 미리 알립니다.
(Review)
결정 트리는 다음과 같은 문제점이 있었다. 이를 위한 해결 방법이 지금 배울 Random Forest이다.

cf) 장점으로는 1) 중요한 feature를 확인할 수 있음, 2) 스케일링이 필요 없음. 이 있다.**암기*
6. Random Forest

한 결정 트리만 쓰기보다는 여러 결정 트리를 만들어서 때려 넣는 느낌이다.. 이를 앙상블(ensemble)이라고 한다. 앙상블을 통해 만든 모델이 Random Forest이다.
- Ensemble

앙삼블의 정의
이러한 앙상블 모델이 기본 모델보다 좋으려면 다음 조건을 만족해야한다. # 앙상블 모델 조건**

서로 독립적 = 다양성을 확보했다
우선, 합칠 base 모델들이 독립적이여야한다.
공부 잘하는 선생님과 공부 못하는 학생이 같이 수험장에 왔다고 생각해보자. 선생님이 학생의 수능 문제를 대신 풀어주는 것은 잘못됐다.. 즉 1) 독립을 유지해야한다. 또한 공부 못하는 학생이 찍는 것보다 시험 점수를 못본다고 생각해보자. 이 친구는 수험장에 올 필요가 없다.. (이건 예시가 좀 너무 한 것 같긴하다..) 각 2) base 모델은 무작위 예측을 수행하는 model 보다 성능이 좋아야한다.
어느정도 공부를 하고, 서로 영향을 안주는 독립적인 사람들 끼리 모였을 때.. 한 시험지를 같이 풀면 시험을 잘 볼 것이다.
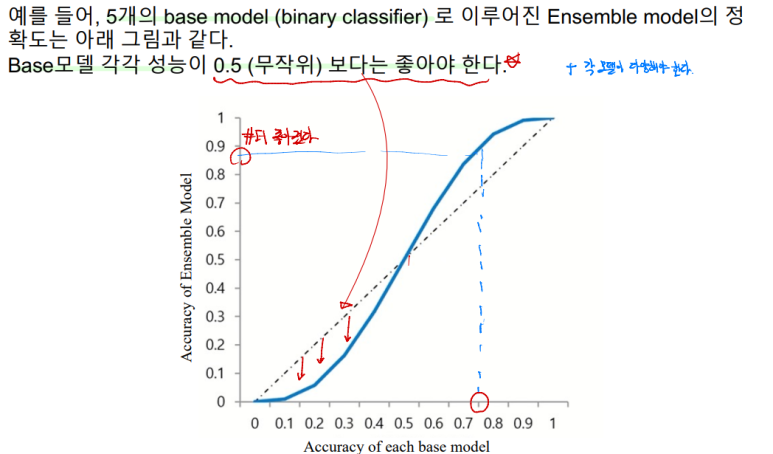
무작위 예측보다 떨어지는 모델들로 앙상블을 진행하면 오히려 안좋다.
# 의사 결정 나무은 앙상블 모델의 base 모델로써 활용도가 높다. 그 이유는 다음과 같다.**
Low computational complexity: 데이터의 크기가 방대한 경우에도 모델을 빨리 구축할 수 있음 • Nonparametric: 데이터 분포에 대한 전제가 필요하지 않음.(다양성을 늘리기 좋다.)
- Random Forest
# Random Forest: 다수의 Decision Tree 에 의한 예측을 종합하는 Ensemble 방법
일반적으로 하나의 Decision Tree 보다 높은 예측 정확성을 보이고, 고차원 데이터에서 중요 변수 선택 기법으로 활용 가능하다. 고차원 데이터에서 중요 변수 선택 기법이란.. 고차원은 쓸모 없는 feature들이 많을 수 있다. 이것들을 빠르게 없앨 때 쓸 수 있는 것이다.


그냥 복원 추출해서 새로운 데이터 셋 만드는 거다
복원 추출로 다수의 Training data를 생성하여 그 Traing data에 대한 각각의 decision tree 모델을 구축하고 예측을 종합하면 된다. 이게 Random forest이다. 걍 이런거구나.. 생각하고 넘어가자. 뒤에서 한 번 더 설명하겠다.
- Key idea of Random Forest

두 특징을 잘 살펴보자.
1) Diversity -> Bagging: Random Forest는 다양성을 갖기 위해 Bagging 방법을 사용한다.

생성할 때, 설명했다.
cf) 이게 왜 좋은지 알기 위해 다른 데이터를 나누는 방법 K-fold data split를 알아보겠다.

K-fold data split
데이터를 K개의 데이터 그룹으로 나누고(한 개의 데이터 포인트가 아니다) 이걸 학습에 이용한다. 이 방식은 원래 데이터 수 만큼의 크기를 갖지 못한다.
이와 달리 복원 추출을 통해 원레 데이터 수 만큼의 크기를 갖도록 샘플링하는 방법이 Bootstrapping이다.

Original Dataset에서 복원 추출을 통해 N개의 개별 데이터셋을 뽑았다. 각 데이터셋을 Bootstrap set이라고 부른다. 각 Bootstrap은 뽑히지 않은 데이터 point에 대한 정보를 갖고 있는다. 이 OOB는 변수의 중요도를 판단할 때 사용된다.

이제 이렇게 만든 샘플들의 예측 결과를 합치면 된다.
우선 간단하게 어떤 클래스가 많은지 비교하여 예측 결과를 합칠 수 있다.

voting 방법 1 - 다수결
만약에 여기에서 추가 데이터셋 5개를 뽑아 5개의 모델을 만들어 예측을 했는데 모두 train acc가 0.001이고, class 0을 예측했다고 해보자. 앙상블 한 결과 예측값이 0나올 수 있다. 하지만 이건 타당하지 않다.(acc가 매우 작으므로..) 그래서 이러한 훈련 acc를 생각하는 voting 방법은 다음과 같다.

voting 방법 2 - 가중치(훈련 정확도를 고려한) 다수결
모든 모델의 훈련 정확도를 더해 분모에 놓는다. 그리고 각 클래스의 훈련 acc들의 합을 분모로 각각 놓는다. 이 결과를 비교하여 큰 값을 갖는 class를 예측으로 내놓는다.
지금까지 설명한게 Key Idea of Random Forest(1)이다. 여러 개의 Training data를 생성하여 각 데이터마다 개별 트리를 구축했다. 이후 이 예측 결과들을 합쳐 예측을 내놓았다. 데이터를 Bootstrap 방식으로 뽑았기에 이 과정을 Bagging이라고 한다.

이제 다음 아이디어를 보겠다. 이제는 합쳐지기 전 각 각의 Decision Tree들이 어떤 과정으로 만들어졌고 예측을 내놓았는지 확인하겠다.
2) Randomness -> Random subspace
우선 고려할 feature의 갯수 d를 설정한다.d는 주어진 변수(feature)의 수보다 적은 수이다. Bootstrap 1이 feature가 15개 있고{1, 2, 3, 4, 5, ....,15}, d = 4로 지정했다고 하자. Random Forest의 각각의 Decision tree는 d개의 변수를 임의로 선택하여 해당 변수들만들 고려 대상으로 하고 그 고려 대상 중에서 노드를 나눌 feature를 결정한다. 예시를 확인하자.

d = 4이므로 첫 분기점에서 feature이 {6, 10, 7, 2}이 임의로 선택되었다.
랜덤하게 나온 feature {6, 10, 7, 2}가 고려 대상이다. 이 중에서 분기를 나눌 feature를 결정한다. feature 2 결정되었다고 해보자.d를 지정하고 d개의 변수를 임의로 선택하여 거기서 노드를 나눌 feature를 선택하는 이유는 Tree의 다양성을 높히기 위해서이다. ensemble model이 base model보다 우수한 성능을 내는 조건을 위로 올라가서 다시 한 번 읽어보자. 이를 위해서이다.

이 과정을 반복하면 된다. 왼쪽 아래 노드에서도 고려 대상 d = 4개를 임의로 뽑고 {3, 8, 11, 9} 그 중 분기를 할 feature를 찾는다. 이를 반복하며 트리를 완성한다.

각각의 Bootstrap들이 모두 이러한 방법으로 tree를 만든다.
- Generalization Error
이 모델 또한 역시 궁극적인 목표는 못보던 데이터에 대해 정확한 예측 즉 일반화 성능을 높히는 것이다. d개의 랜덤한 feature에서 골라 tree를 만들었는데 과연 이게 일반화 성능이 괜찮을까? 그리고 이 일반화 성능을 좋게 하는 방법은 무엇인지 알아보자.

일반화 에러에는 다음과 같은 상한이 있다. 이러한 상한을 줄여 일반화 에러를 줄이고 싶을 것이다.
(1) Tree가 서로 상관 관계가 낮을 수록, 다양한 특성의 조합을 학습하여 넓은 데이터 분포를 커버하고, 일반화 에러가 감소한다.
(2) 트리가 높은 정확도로 예측을 할 수록, 전체 모델의 일반화 에러는 감소한다.
(쉽게 말하면 상관 없는 애들끼리 묶여야, 각각의 트리가 정확도가 높아야 일반화 에러가 감소한다.)
- Variable Importance(변수의 중요도)
Random Forest는 변수의 중요도를 표현할 가중치도 없고, 일반적인 decision tree와 달리 맨 위 노드에서 선택한 feature가 가장 중요한 feature도 아니다. 랜덤한 d개의 feature 중에서 선택했기 때문이다.
Random forest에서 어떤 변수(feature)가 데이터를 나눌 수 있는 중요한 것인지 변수의 중요도를 간접적으로 구한다.

1단계) 각각 Bootstrap의 out of bag(OOB)를 구한다. OOB란 원레 데이터셋에는 있지만, 복원 추출한 Bootstrap에는 없는 데이터 포인트를 말한다.

2단계) 임의로 뒤섞은 데이터 집합에서 OBB Error를 구함.
'학부 수업 > 데이터마이닝' 카테고리의 다른 글
| 8. Support Vector Machine with Soft Margin (3) | 2024.06.19 |
|---|---|
| 7. Support Vector Machine with hard-margin (2) | 2024.06.17 |
| 5. Decision Tree (4) | 2024.05.20 |
| 4. Linear Models (1) | 2024.05.20 |
| 3. K-Nearest Neighbors (KNN) (1) | 2024.05.20 |