(서울시립대학교 인공지능학과 노영민 교수님의 데이터 마이닝 강의를 정리함을 미리 알립니다.)
2주차. Supervised Learning(지도 학습)
# Supervised Learning

주어진 사진(데이터)을 보고 강아지라고 예측하고 싶다.. by 지도학습
* 알려진 예시(훈련데이터.. Labeled Data 겠지....)를 일반화한 의사 결정 과정.
(Decision-making processes by generalizing from known examples(training data))
* 유저는 입력과 원하는 출력 쌍을 알고리즘(모델)에 제공하고, 알고리즘은 입력이 주어지면 원하는 출력(desired output)을 생성하는 방법을 찾는다.
(The user provides the algorithm with pairs of inputs and desired outputs, and the algorithm finds a way to produce the desired output given an input.)

* 알고리즘은 이전에 본 적 없는 입력에 대한 출력을 생성할 수 있다. # 예측 # 일반화(generalization)
(The algorithm can create an output for an input it has never seen before with out any help from a human. (generalization, 일반화))
1주차에 설명한 대로, 모델에 Labeled training dataset이 주어진다. # input와 결과(output)이 페어로 주어짐..
여기서 output 값인 y는 lable 혹은 target이라고 부른다. (혹은 Ground Truth..)

목적은 결과를 모르는 미래 input에 대한 예측이다.

labeled dataset의 예시.
Row(행)은 data poion, instance, object 등으로 불린다.
Column(열)은 variable, attribute, feature 등으로 불린다.(output 열만 target이라고 부른다)
# 지도학습의 유형 (Types of Supervised Learning)
1) 분류(Classification) : 클래스 라벨을 예측한다.

스팸 메일인지, 아닌지 labeled data를 주고, 새로운 메일이 스팸인지 아닌지 예측한다.
->1_1) 이진분류(Binary Classification) : 강아지 인지 아닌지.. (말 그대로 binary..)
1_2) 다중 클래스 분류(Multi-class Classification) : 강아지 인지, 고양이 인지..

이진분류 vs 다중 클래스 분류
1_3) 다중 라벨 분류 : 고양이, 강아지 사진에 다 있는 경우....

2) 회귀(Regression) : 연속적인 숫자를 예측한다. (continuity in the output)

회귀는 이 그림으로 이해하면 된다. # 출력의 연속성
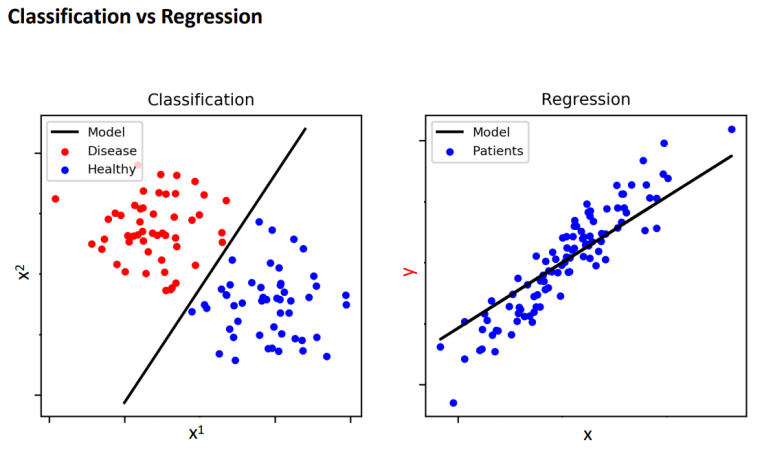
분류와 회귀의 차이.. 그림으로 잘 이해하자.

총 정리.. 여기 까진 그냥 그렇구나. 이런게 있구나.
# 그래서 지도학습 뭐 배울건데?

이걸 이제 배울거야.
많은 알고리즘에는 분류와 회귀가 있다. 이 두 가지를 모두 배울 것이다. 가장 널리 사용되는 기계 학습 알고리즘을 검토하고, 데이터로 부터 모델이 학습하는 방법과 예측하는 방법을 설명하고 각 알고리즘의 장단점을 분석할 것이다.
2주차_2. Generalization(일반화)
# Generalization(일반화)
* 지도 학습에서는 새롭고, 보이지 않는 데이터에 대한 정확한 예측을 수행하는 모델을 구축하려고 한다. 이것을 바로 일반화라고 한다. # 우리는 최대한 정확하게 일반화할 수 있는 모델을 구축하고 싶다. (학습 목표)
# 문제 + 답지 주고, 새로운 문제에 대한 정확한 답을 내놓도록 하는 것을 Generalization 라고 한다.
(In supervised learning, we want to build a model that will make accurate predictions on new, unseen data, which is called generalization.)
* 일반화 성능을 평가하기 위해서 test set을 사용한다. 이 데이터는 훈련 세트(training set)과 별도로 수집된 데이터이다. # 훈련 시키지 않은 데이터를 남겨둔다. (To evaluate generalization performance, we use a test set that were collected separately from the training set.)
* 모델이 test set에 대해 정확한 예측을 만들 수 있다면, 우리는 training set에서 test set으로 일반화할 수 있다 말한다. (If a model can make accurate predictions on the test set, we say it can generalize from the training set to the test set.)
-> 결국 지도학습의 목적은 일반화 성능을 극대화하는 것이다.
(The objective of supervised learning is to maximize the generalization performance)
여기서 잘 못 학습된 경우의 두가지 경우를 알아야한다.
1) Overfitting(과적합) : 우리가 갖고 있는 정보 양에 비해 모델이 너무 복잡한 경우.
모델이 훈련 데이터의 특수성(particularities)에 대해서 너무 가깝게 적합된 경우.
(-> 학습 데이터만 ㅈㄴ 잘 맞추추는 경우, 새 데이터로 일반화 할 수 없다..)
2) Underfitting : 우리가 갖고 있는 정보의 양에 비해 모델이 너무 단순하다.
모델이 데이터의 모든 측면과 가변성을 포착하지 못한다. 즉 훈련 세트에서도 제대로 작동x..

왼쪽으로 갈 수록 Underfitting.. 오른쪽으로 갈 수록 Overfitting..
# Model Complexity (모델 복잡성)
모델의 복잡성은 훈련 데이터셋에 포함된 입력값의 변화와 매우 밀접하게 연관되어있다.(It’s important to note that model complexity is intimately tied to the variation of inputs contained in your training dataset.)
-> 즉 입력 데이터의 포인트가 다양할수록 모델은 더욱 복잡해진다. 입력 데이터가 다양할 수록 복잡한 모델을 overfitting 없이 사용할 수 있다.
일반적으로 많은 데이터 포인트를 수집하면 많은 다양성을 얻을 수 있으므로 더 복잡한 모델을 사용할 수 있다.
(The more variety of data points included in the train dataset, the more complex models can be used without overfitting. - In general, collecting more data points gives you more diversity, so the larger your tr ain data set, the more complex models you can build)

# 적당히..
# The trade-off (절충안)

t0일때 모델의 일반화 성능을 극대화하는 지점이다. # 충분한 시간 훈련했다 가정한다.
# Model Parameters/Hyperparameters 용어정리
1) Parameters(매개변수) : 모델 내부 구성(Model Internal Configuration)
-> 값은 모델 학습을 통해 파생된다. 새로운 데이터에 대한 예측을 위해 사용된다.
2) Hyperparameters(초매개변수) : 모델 학습을 위한 구성 변수 # 내가 조절하는 변수 ex) 러닝 타임..
-> 값은 모델 학습 전에 설정된다. 모델의 복잡성과 학습 알고리즘의 동작을 제어한다.
* 초매개변수가 주어지면, 학습 알고리즘은 훈련 데이터로부터 매개변수를 학습한다.
# Training, Validation, and Test (데이터 셋의 구분)

Testing data를 빼놔야한다. 조심해야할 실수 잘 봐두자.
Training set : 훈련 데이터... 모델의 매개변수를 학습한다. (파생된다.)
Validation set : 검증 데이터.... 모델의 초매개변수(hyperparameters)를 선택한다. # 목적
# hyperparameters를 몇으로 하니까 validation set에서 ~하더라.. 이런거 결정.. 결정되면 vaildation set를 training set에 편입시키고 학습을 시킨다.
Test set : 모델의 일반화 능력을 최종평가하기 위함. (학습 데이터에 포함되지 않는 새로운 데이터, 답도 아는 거지)

traing set과 vaildation set을 나눌 때 문제점. 균질화 후 나누면 좋을 때가 있다.. 이정도 알고 넘어가자.
# Performance Evaluation (성능 평가, 지도학습의 큰 장점..!) *********
1) 분류(Classification)에 대한 성능 평가.
주어진 데이터에 대한 * 정확도(Accuracy)

Accuracy(정확도) 정의... I 함수는 맞으면 1, 아니면 0을 결과로 하는 함수이다.
전체 데이터 셋 갯수 중 예측 잘 한 데이터 셋 비율.. 이걸 백분율로 표기한 것.
ex) 5개의 test 데이터가 있는데 3개를 예측을 잘 했다면 Accuracy = 3/5 * 100 = 60..

* 오답률(Error Rate)은 이거겠지.
#### 중요 #### 시험 문제 필수..
* Confusion Matrix(혼란 매트릭스) - 여기서 Accuracy, Precision(정밀도), Recall(검출율)에 대해 배울 것임.

뒤에서 부터 읽는다.
Tip) 이게 많이 헷갈린다. 매트릭스 자체를 외운다 일단.... 그리고 뒤에서 부터 읽는다....
FP -> 뒤에서 부터 P: 맞다고 했는데 -> F 아닌거.. 즉 실제는 거짓인 경우.
###### 4가지 수치를 꼭 기억한다. #########
1) Accuracy(정확도) : 전체에서 내가 내놓은 정답이 맞는 비율 (내가 내놓은 답이 뭐든 상관 없이 맞는 경우)

# 대각선
2) Precision(정밀도) : 내가 진짜일 것(True)이라고 예측한 것 중 맞는 경우...

진실을 맞추는 건 정밀해야 한다..
3) Recall(검출율) : 실제 True인 것중에 내가 True라고 예측한 경우. # 정밀도와 잘 구분해야한다. 진짜 중에 내가 맞춘거..

tip) 정의를 외운다, 그림으로 외운다....
4) F1-Scroe(조화 평균) ** 공식.. # Imbalanced data 때문에 이러한 수치가 필요하다.

잘 외워놓자.....
# Mean Average Precision(mAP) (이런게 있다.. 따로 더 찾아봐야 할 것 같다..)

각 클래스 AP들의 평균.
threshold를 조정하여 recall, precision을 조정할 수 있다.. (trade-off....)
진짜 얼굴만 뽑기 위해서 threshold를 높혀놨다고 해보자. recall 값은 올라가지만.. precision은 낮아진다..
cf) recall(검출율) : 진짜 중에 내가 진짜라고 판정한 비율, precision(정밀도) : 진짜라고 한 것중에 진짜인 비율..

threshold를 올려도 맨 왼쪽 여자 얼굴을 판정하지는 못했으니까, recall은 100이될 수 없다. 강의 노트를 한 번 더 보자..
Confusion Matrix가 2x2가 아닐 수 있다.. 이때는 판정마다 다르게 계산해줘야한다. ## ㅈㄴ 중요****

모델 1의 Accuracy(정확도), precision(정밀도), recall(검출율)을 계산해보자. # 정의를 잘 생각해라.

정밀도, 검출율은 각 클래스마다 구한 후 평균내야 한다. 이 평균을 통해 F-Score가 계산된다.
# 정의) Macro-average F1-Score 각 클래스에 대한 F1-Score를 독립적으로 계산하고 평균..
각 클래스 별의 F1 Score를 구하고.. 이를 평균내야한다. recall, precision과 잘 구분하라..
(계속 예측 지도 학습 모델에 대한 성능 평가를 말했다.)
2) 회귀(Regression)에 대한 성능 평가. # 암기

이 수치를 이해하고 싹 다 외운다.
.. ppt 뒤에 이제 sklearn 실습 있다.. 공부하고 꼭 이해하고 넘어간다.
과제)

'학부 수업 > 데이터마이닝' 카테고리의 다른 글
| 6. Random Forest (3) | 2024.05.20 |
|---|---|
| 5. Decision Tree (4) | 2024.05.20 |
| 4. Linear Models (1) | 2024.05.20 |
| 3. K-Nearest Neighbors (KNN) (1) | 2024.05.20 |
| 1. Introduction 데이터 마이닝이란? (3) | 2024.05.20 |