서울시립대학교 인공지능학과 노영민 교수님의 데이터 마이닝 강의를 정리함을 미리 알립니다.
이 수업은 데이터 마이닝에 대한 기본적인 개념을 이해하고, 대표적인 알고리즘을 학습하는데 목표를 둔다.
1주차. Introduction
# 데이터 마이닝이란 무엇인가?
데이터에서 지식을 발견하고, 데이터에서 유익한 패턴을 추출한다.
특정 알고리즘이나 기계 학습 기술을 사용한 데이터 분석이다.

데이터 마이닝의 예시. 논문에서 키워드를 기준으로 지식을 발견한다.
# 데이터 마이닝과 기계학습의 차이.

데이터 마이닝은 가지고 있는 데이터에서 현상 및 특성을 발견하는 것이 목적이다. # 지식을 발견
머신러닝은 기존 데이터를 통해 학습을 시킨 후 새로운 데이터에 대한 예측값을 알아내는 데 목적이 있다. # 예측
# 데이터 마이닝 프로세스

데이터 마이닝 프로세스의 일반적인 관점
1) 데이터 크롤링(Data crawling) 등을 통해 입룍 데이터를 수집한다.
이 때 양질의 데이터를 수집하는 것이 중요하다.
2) 전처리: 수집한 데이터를 전처리. 데이터를 정리 및 축소하는 과정이다.
(Cleaning, Normalization, Integration)

중복 데이터를 제거하거나, 통계적 정규화, 샘플링 및 이산화 기술을 사용한다.
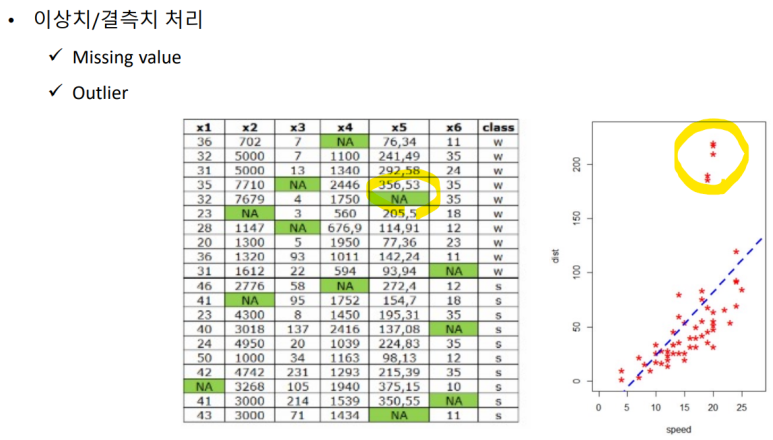
이상치/ 결칙치를 처리한다.(좌: 누락값, 우: 이상치(Outlier) ).

이때 학습 데이터를 늘리기 위해 데이터를 증대(Data augmentation)하기도 한다. 고냥이를 가리기도 하고 뒤집기도 하고.. 학습 데이터를 확보하기 위해서.....
3) 데이터 마이닝.
이렇게 전처리 된 데이터를 데이터 마이닝 한다.
Classification(분류), Clustering(군집화), Pattern Mining을 할 수 있다.
4) 후처리(Post process) : Evaluation(평가), Interpretation(해석), Visualization(시각화)

데이터 마이닝 이후 평가, 해석, 심상을 한다. 이게 후처리이다.
# Supervised Learning : 정답을 알려준 학습.. # 지도학습 # 답지랑 문제 같이 주고 시험보기
Training data with class labels. -> 클래스 라벨 있는 훈련 데이터로 진행된다.
Prediction of classes of data with no class labels. -> 학습 후 클래스 레이블이 없는 데이터의 클래스를 예측.

음.. 걍 이런게 있구나. 2주차에 더 공부한다.
# Unsupervised Learning : 정답을 알려주지 않은 학습.. # 비지도 학습 # 문제만 계속 주고 시험보기
Grouping data with no class labels. -> 클래스 라벨이 없는 훈련 데이터로 학습이 진행된다.
Dimensionality reduction with a purpose. -> 목적에 따른 차원 축소...


'학부 수업 > 데이터마이닝' 카테고리의 다른 글
| 6. Random Forest (3) | 2024.05.20 |
|---|---|
| 5. Decision Tree (4) | 2024.05.20 |
| 4. Linear Models (0) | 2024.05.20 |
| 3. K-Nearest Neighbors (KNN) (1) | 2024.05.20 |
| 2. Supervised Learning(지도 학습) (0) | 2024.05.20 |