https://arxiv.org/abs/2203.08195
DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection
Lidars and cameras are critical sensors that provide complementary information for 3D detection in autonomous driving. While prevalent multi-modal methods simply decorate raw lidar point clouds with camera features and feed them directly to existing 3D det
arxiv.org
- Abstract
LiDAR와 카메라는 3D detection을 위해 상호 보완적인 정보를 제공한다.
기존의 multi-modal 방법들은 단순히 raw한 LiDAR point cloud에 카메라 feature를 추가하고 이를 모델에 집어넣는다. 하지만 해당 논문에서는 raw point가 아닌 deep LiDAR feature에 카메라 feature를 결합했을 때 더 나은 성능을 낼 수 있음을 보여준다.
하지만, feature들은 종종 augmentation되거나 aggregation된다. 그렇기에 두 feature를 효과적으로 정렬하는 것이 가장 큰 도전 과제이다. 본 논문에서는 이를 위해 회전과 같은 geometric-related augmentations를 되돌리는 1) InverseAug 그리고 융합 과정에서 이미지와 라이더 feature 사이의 correlation을 동적으로 포착하기 위해 cross-attention을 사용하는 2) LearnableAlign 두가지 새로운 기술을 제안한다.
cf. 동적으로 포착: 실시간으로 변화하는 감지하고 반응.. 포착
InverseAug와 LearnableAlign을 기반으로 DeepFusion이라는 generic multi-modal 3D detection models를 개발. 기존 방법보다 더 뛰어난 성능을 보인다. Waymo Open Dataset에서 최첨단 성능을 달성했으며, 입력 손상 및 분포 밖 데이터에 대해 강력한 모델 견고성을 보인다.
- Introduce
라이더와 카메라 두 가지 센서는 자율주행을 위한 상호 보완적인 유형의 센서이다. 3D object detection를 위해 라이더는 저해상도 형태 low-resolution shape와 깊이 정보를 제공하고, 카메라는 고해상도 high-resolution shape와 질감 정보를 제공한다. 이러한 관계에 의해 두 센서의 결합이 최고의 3D object detector를 제공할 것으로 예상할 수 있다. 하지만 해당 논문이 작성된 당시 SOTA 모델들은 라이더 입력만 사용하고 있었으며 두 센서 신호를 효과적으로 융합하는 건 어려움으로 남아 있었다. 이 논문에서는 이 문제에 대해 효과적인 해결책을 제시한다.
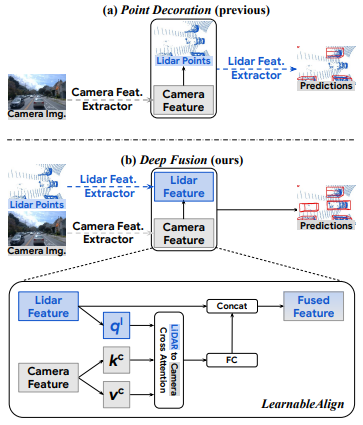
위 figure 1을 보자. 기존의 라이더와 카메라 융합 방법은 크게 두 가지로 나뉜다.
a) 라이더 포인트 클라우드의 포인트에 해당하는 카메라 feature를 추가하여 초기 단계에서 특징을 융합하는 방법.
b) feature 추출 후에 특징을 결합하는 중간 수준의 융합 방법
이 두 접근 방식 모두에서 가장 큰 과제는 라이더와 카메라 feature 간의 대응관계 correspondence를 파악하는 것이다.
해당 논문은 효과적인 중간 수준의 융합 즉 2번째 방식의 융합을 가능하게 하는 InverseAug와 LearnableAlign이라는 두 가지 방법을 제안한다.
- InverseAug 개요
InverseAug는 기하학적으로 관련된 랜덤 회전과 같은 데이터 증강을 역으로 적용하고, 원래의 카메라와 라이더 파라미터를 사용하여 두 양식의 데이터를 연결한다.
- LearnableAlign 개요
LearnableAlign은 크로스 어텐션을 활용하여 라이더 특징과 해당하는 카메라 특징 간의 상관관계를 동적으로 학습한다.
cf. cross-attention이란?
이 두 가지 제안된 기술은 기존 모델에 쉽게 적용할 수 있으며, 정렬된 multi-modal feature를 융합할 때, 훨씬 높은 해상도의 카메라 신호가 모델의 인식 및 위치 파악 능력을 크게 향상시킨다. 이러한 이점으로 장거리 object detection에도 유용하게 사용될 수 있다. # 두 기술은 아래서 더 설명할 것이다
이러한 방식을 사용해 개발한 multi-modal 3D detection models DeepFusions은 end-to-end로 학습될 수 있고, 기존의 많은 복셀 기반 3D 감지 모델들과 호환되는 일반적인 빌딩 블록이라는 이점이 있다.
해당 모델의 주요 기여는 세 가지로 요약될 수 있다.
1) 3D multi-modality detectors에서 deep feature alignment를 체계적으로 연구한 최초
2) 정확하고 견고한 3D 객체 감지기를 위해 deep feature alignment 을 달성하는 InverseAug와 LearnableAlign을 제안
3) Waymo Open Dataset에서 최첨단 성능을 달성
- Related Work
- 3D Object Detection on Point Clouds
Point cloud는 unordered sets으로 많은 3D object detection들은 이를 바로 네트워크에 적용한다.
ex) PointNet, PointNet++
https://dogunkim.tistory.com/44
PointNet 논문 리뷰
딥러닝을 이용해 Point cloud를 처리하는 방법론들에 대해 공부 1. PointNethttps://arxiv.org/abs/1612.00593 PointNet: Deep Learning on Point Sets for 3D Classification and SegmentationPoint cloud is an important type of geometric data st
dogunkim.tistory.com
https://dogunkim.tistory.com/45
PointNet++ 논문 리뷰
2. PointNet ++ https://arxiv.org/abs/1706.02413 PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric SpaceFew prior works study deep learning on point sets. PointNet by Qi et al. is a pioneer in this direction. However, by design Poin
dogunkim.tistory.com
여러 연구들이 PointNet과 유사한 계층을 사용하여 feature를 학습한다.
라이다 데이터는 깊이 정보가 포함된 거리 이미지로 변환될 수 있으며, 이를 사용해 3D 경계 상자를 예측하는 연구가 존재한다.
point cloud를 바로 사용하는 것과 달리 또 다른 3D 탐지 방법들은 라이다 포인트를 voxels 또는 pillars 으로 변환하여 두 가지 자주 사용되는 3D 탐지 방법인 voxel-based 그리고 pillar-based 을 사용한다.
ex) VoxelNet, SECOND
3D 복셀을 처리하는 데 비용이 많이 들기 때문에 PointPillars 와 PIXOR는 3D 복셀을 단순화하여 동일한 z축을 가진 모든 복셀을 하나의 기둥으로 압축한 조감도 2D pillars으로 변환한다.
쉽게 이야기하면.. 3d를 처리하는 건 비용이 많이 들기에 pointcloud를 2D pillars로 바꿔 2D convolution에 사용하고 싶은 거다. 본 논문에서도 라이다 포인트 클라우드를 처리하기 위한 기본 접근 방식으로 PointPillar를 선택한다.
- Lidar-camera Fusion
monocular detection은 라이다 포인트 클라우드에 의존하지 않고, 2D 이미지에서 직접 3D 상자를 예측한다. 하지만 2D 이미지에 깊이 정보가 없기에 2D 이미지 픽셀에 대한 깊이를 암시적으로 또는 명시적으로 예측해야만 하며 이는 어려운 작업이다. 그렇기에 최근에는 3D 탐지를 개선하기 위해 라이다와 카메라 데이터를 결합하는 추세이다. 2D 이미지에서 물체를 먼저 탐지한 후 그 정보를 사용해 포인트 클라우드를 추가 처리한다. 기존의 연구들은 2단계 프레임워크를 적용, 객체 인식을 위해 두 가지 서로 다른 센서를 단계적으로 결합했지만, 이 논문은 복잡한 두 단계의 융합 과정을 거칠 필요 없이 기존의 3D 복셀 기반 탐지 방법에 간단하게 적용할 수 있다.
- Point Decoration Fusion
1) PointPainting
LiDAR가 얻은 3D 데이터에 카메라 이미지에서 추출한 정보인 semantic segmentation을 통해 얻은 의미 정보를 추가하여 더 풍부한 3D 객체 인식 성능을 기대하는 방식
2) PointAugmenting
PointPainting의 의미 정보를 나타내는 semantic score 한계 지적. 카메라 이미지 위에서 2D object detector에서 추출된 심층 특징을 사용해 LiDAR 포인트를 증강할 것을 제안.
-> 즉 feature를 뽑아내서 그걸 합치자고 제안. 맨 위 figure1에 a) 방식이다.
하지만 이렇게 feature를 뽑아내는 방식은 2D object detector과 같은 사전 학습된 모듈에 크게 의존한다. 뽑아낸 feature는 추출한 특징들은 LiDAR 포인트에 결합되고, 이를 복셀화하여 bird-eye view 의사 이미지를 생성한다.
- Mid-level Fusion***
Deep Continuous Fusion, EPNet, 그리고 4D-Net 등 이미 2D와 3D BACKBONE 간의 정보를 공유하여 두 형식을 융합하려고 시도하였다. 즉 두 센서 데이터를 백본 네트워크 레벨에서 결합한다는 것이다. 그러나 해당 논문은 기존 연구에서 카메라와 LiDAR 데이터를 효과적으로 정렬하는 방법이 부족하다는 점을 지적하며, 실험을 통해 정렬이 3D 객체 탐지 성능에 매우 중요한 요소임을 강조. # 사실 합칠 때 정렬이 이 논문의 핵심..
# 정렬이 어려운 이유
1) 데이터 증강 ** # augmentation
기존 벤치마크 데이터 셋 Waymo Open Dataset에서 최고의 성능을 달성하기 위해, 융합 단계 이전에 LiDAR 포인트와 카메라 이미지에 다양한 데이터 증강 전략이 적용된다. 예를 들어 라이더 데이터를 z축으로 회전하는 Random Rotation은 주로 LiDAR에 적용되지만, 카메라에는 적용되지 않아서 이후 feature 정렬이 어려워짐.
>> 프로젝트 진행할 때, 언급. 데이터 증강 전략을 사용했을 때의 어려움 언급하기.
2) 데이터 응집 # aggregation
LiDAR 데이터가 voxel로 변환되면서 하나의 보셀이 여러 카메라 이미지의 특징과 매칭된다. 하지만 모든 카메라 특징들이 3D detection할 때 똑같이 중요한게 아님. 어떤 카메라 데이터는 중요한 반면, 다른 데이터는 덜 중요할 수 있다.
cf. 맨 앞 초록에서 이에 대해 한 번 언급했다. 연결해서 읽으면 더 좋다.
- DeepFusion

- Deep Feature Fusion Pipeline 3-1
figure1 a)의 기존의 방법들은 카메라의 특징을 추출하기 위해 사전 학습된 모델을 사용함. 이후 원시 LiDAR 포인트에 추출된 카메라 특징을 결합, 3D 포인트 클라우드 객체 감지 프레임워크로 전달한다. 이 논문은 기존의 방법은 다음과 같은 두가지 문제를 보이며 이를 해결하기 위한 deep feature fusion pipeline를 제안한다.
문제점 1) 카메라 feature과 라이더 데이터가 같은 모듈에 전달될 때, 데이터 구조가 모듈에 적합하지 않은 경우

카메라 특징은 포인트 클라우드 데이터를 처리하도록 특별히 설계된 여러 모듈로 전달된다. 즉 카메라 특징이 LiDAR 데이터를 처리하는 모듈로 전달된다. 예를 들어, PointPillars [16]이 3D 탐지 프레임워크로 채택되면, 카메라 특징은 원시 포인트 클라우드와 함께 보셀화되어 bird’s eye view 의사 이미지를 구성한다. 하지만 이러한 보셀화는 카메라 정보에 적합하지 않다는 문제가 있다.
>> 문제점 1 해결 : 심층 카메라와 LiDAR 특징을 융합하여 카메라 신호가 포인트 클라우드용으로 설계된 모듈을 거치지 않도록 한다.
문제점 2) 카메라 feature를 뽑아낼 때의 학습이 독립적. 이로 인한 최적화 실패

둘째, 카메라 특징 추출기는 다른 독립적인 작업에서 학습되기 때문에, i) 도메인 차이, ii) 주석 작업의 필요성, iii) 추가적인 계산 비용, 그리고 iv) 더 중요한 특징이 종단 간 방식으로 학습되지 않고 경험적으로 선택되기 때문에 최적화되지 않은 특징 추출로 이어질 수 있다.
cf. 종단 간 = end to end. 모델이 데이터 전처리, 특징 추출, 결과 예측 등을 모두 하나의 네트워크 안에서 학습하는 방식.
>> 문제점 2 해결 : 컨볼루션 층을 사용하여 카메라 특징을 추출하고, 이러한 컨볼루션 층을 네트워크의 다른 구성 요소들과 함께 종단 간 방식으로 학습한다. # 독립적인 추출기를 써야하지만, CONV 층 쓰면 최적화된다.... 이런 내용인 듯.

파이프라인을 요약하면..
1) LiDAR 포인트 클라우드는 기존 LiDAR 특징 추출기로 전달되어 LiDAR 특징을 추출.
2) 카메라 이미지는 2D 이미지 특징 추출기로 전달되어 카메라 특징을 얻는다.
3) 카메라 특징은 LiDAR 특징과 융합 # 융합 과정은 뒤에서 더 자세히 설명한다.
4) 융합된 특징은 선택된 LiDAR 탐지 프레임워크의 나머지 구성 요소에서 처리되어 탐지 결과를 얻는다.
이러한 설계는 다음과 같은 두 장점을 갖는다.
장점 1) 풍부한 문맥 정보를 가진 고해상도 카메라 feature를 유지할 수 있다.
기존 방법들은 카메라 이미지를 bird's eye view로 변환하는 과정에서 해상도가 떨어지거나 정보가 손실될 수 있는데, 새로운 방법은 이러한 문제를 해결하여 카메라 고해상도의 특징을 유지한다.
# 이해가 안된다면 위 문제점1을 다시 한 번 읽어보자. 이를 해결하면서 얻은 장점이다.
장점 2) 도메인 차이 및 주석 문제들이 완화되고, 종단 간 학습 덕분에 더 나은 카메라 특징을 얻을 수 있다.
각각의 특징 추출기에서 따로 추출한 후, 이 데이터를 심층(feature level)에서 융합하여 하나의 네트워크로 학습을 진행한다는 점에서 이러한 장점을 얻을 수 있다.
# 이해가 안되면 위 문제점2를 다시 한 번 읽어보자. 이를 해결하면서 얻은 장점이다.
cf. end to end 즉 종단 간 학습은 여기서 특징 융합부터 최종 탐지까지의 모든 과정이다. '네트워크'가 LiDAR와 카메라 데이터를 결합하여 최종적인 3D 객체 탐지 결과를 내는 과정이 자동으로 최적화된다. 중간에 사람이 개입해서 따로 조정할 필요 없이 네트워크가 자동적으로 최적의 방법을 학습한다.
하지만.................. 이러한 모델에도 단점은 존재한다. 입력 단계에서 특징을 결합하는 것과 비교했을 때, 심층 특징 단계에서는 카메라 특징과 LiDAR 신호를 정렬하는 것이 더 복잡하다. 예를 들어 LiDAR와 카메라 데이터를 각각 다른 방식으로 증강할 경우, 두 데이터의 정렬이 정확하지 않아 융합 단계에서 문제가 생길 수 있다. 논문은 이에 대한 문제를 확인하고 해결책을 제시한다.
- Impact of Alignment Quality 3-2 # 정렬이 융합에 주는 영향
심층 특징 융합에서 정렬이 주는 영향을 보여주는 부분이다. 실험을 위해 모든 데이터 증강을 비활성화하고 RandomRotation의 크기만을 LiDAR 포인트 클라우드에 적용하여 심층 융합 파이프라인을 훈련했다.

데이터 증강이 커질 수록, Single-Modal과의 성능 차이가 없다... 데이터 증강인 회전 각도가 커질수록 카메라와 LiDAR 데이터를 융합한 효과가 감소하는 것이다. 이러한 실험을 바탕으로 정렬이 정확하지 않으면 카메라 입력의 이점이 미미해진다는 결론을 보인다.
- Boosting Alignment Quality # 정렬을 위한 방법론
1) InverseAUG # 데이터 증강을 거꾸로 적용하여 3D 데이터와 2D 카메라 데이터를 정확하게 정렬하기
데이터 증강은 모델의 성능을 높이기 위한 필수적인 기술이지만, 과적합 문제도 동시에 발생할 수 있음을 지적.
cf. Table1 Single-Modal에서도 데이터 증강을 주면, 모델의 성능이 올라감을 볼 수 있다. 하지만 계속 말 했듯이.. 몇 번을 말하는 건지..ㅜ 데이터 증강 때문에 심층 특징 단계에서는 정렬이 어렵다.

위 그림을 보면 데이터 증강이 적용된 후, LiDAR와 카메라 데이터를 기존 방식으로는 제대로 정렬할 수 없음을 보인다.
단순히 원래 LiDAR 및 카메라 매개변수를 사용하여 해당 카메라 특징을 2D 공간에서 찾을 수 없다.
# cannot directly project 부분을 보면 된다.
InverseAug는 데이터 증강 시 사용된 매개변수를 저장하여 나중에 이를 복원하는 방법으로 정렬 문제를 해결한다.
ex) RandomRotate [46]의 회전 각도를 저장해놓고, 이를 통해 복원
융합합 단계에서 InverseAug는 이러한 모든 데이터 증강을 역으로 적용하여 3D 키 포인트의 원래 좌표를 찾고 c), 해당 카메라 공간에서 대응되는 2D 좌표를 찾는다. # 위 그림에서 b->c로 복원 이후 사진과 매칭
2) LearnableAlign
# 정렬은 하나의 보셀에 여러 픽셀이 대응되는 문제 제기
기존의 입력 레벨 정합은 주어진 3D 라이더 포인트들이 카메라 픽셀에 1대1 매핑으로 위치할 수 있다. 반면... DeepFusion 파이프라인에서 심층 특징을 융합할 때는 하나의 복셀에 여러 개의 카메라 픽셀이 대응되기 때문에 정렬이 더 복잡하다.
cf. voxel는 라이더 포인트들의 집합인 3차원 공간의 작은 큐브. 이렇기에 한 복셀에 여러 카메라 픽셀이 대응된다.
cf. 단순하게 픽셀들을 average poll에 넣어서 합치면 되는가? 생각할 수 있다. 하지만 이는 정보 손실을 초래할 수 있다.
# 해당 논문은 모든 카메라 픽셀이 동등하게 중요하지 않은 것에 초점을 둬 문제를 해결한다.
ex) 자동차를 탐지한다고 하자. 탐지할 객체인 자동차의 특징을 포함하는 픽셀은 중요한 반면.. 도로, 하늘등의 정보를 담은 픽셀은 별로 중요하지 않다.
LiDAR 특징과 가장 관련 있는 카메라 특징을 더 잘 정렬하기 위해, 논문는 두 모달리티 간의 상관관계를 동적으로 포착하는 교차 주의 메커니즘을 사용하는 LearnableAlign을 도입한다. cross-attention을 사용하여 두 모달리티 간의 상관관계를 동적으로 계산한다.

구체적으로 모델을 보면서 이해해보자. 하나의 라이더 Voxel과 그것과 연관되는 N개의 카메라 feature가 입력으로 있다고 하자.
- 우선 3개의 fully-connected layers를 통해 보셀을 쿼리 $q^l$로, 그리고 카메라 특징을 키$k^c$와 값$v^c$로 변환한다.
- 이후 cross-attention에서 쿼리 $q^l$과 키$k^c$의 내적을 통해 1XN 상관 행렬을 만든다.
이 행렬은 하나의 보셀과 여러 카메라 픽셀들 간의 상관관계를 나타낸다. 이 행렬을 통해 어떤 카메라 픽셀이 해당되는 복셀과 더 강하게 연결되어 있는지 확인할 수 있다. 이를 유사성 행렬 affinity matrix라고 부른다.
- 이러한 유사성 행렬을 softmax 함수에 넣어 정규화한 후, 이를 사용해 카메라 정보를 가중치에 따라 합산한다.
- 집계된 카메라 정보는 완전 연결층에서 처리된 후, 원래 LiDAR 특징과 최종적으로 결합한다. #Fused Feature
- 최종 출력 Fused Feature는 PointPillars 또는 CenterPoint와 같은 표준 3D 탐지 프레임워크에 입력되어 모델 훈련에 사용된다.
핵심은..
1. 핵심은 원시 라이더 데이터에 이미지의 특징을 정합하는 Point Decoration Fusion은 정보 손실, 최적화 등의 한계를 가지니 라이더, 이미지 각각 특징을 추출하고 정합하자.
2. 성능을 위해 데이터 증강을 한 경우 라이더와 사진의 정렬이 어렵다. -> InverseAUG를 통해 데이터 증강을 기억하고 거꾸로 돌려서 정합하자.
3. 특징을 추출하는 과정에서 라이더 데이터에 복셀화가 일어나는데 이 때 픽셀과의 1대1 대응이 안된다. -> LearnableAlign로 상관 관계를 계산해서 가장 맞는 픽셀을 합치자
인 것 같습니다.
'논문 > CV' 카테고리의 다른 글
| 논문 리뷰) Knowledge Distillation for Efficient Instance Semantic Segmentation with Transformers [CVPR 2024 Workshop] (0) | 2025.04.03 |
|---|---|
| PointNet++ 논문 리뷰 (2) | 2024.09.19 |
| PointNet 논문 리뷰 (2) | 2024.09.19 |