Ch 02. Point Cloud Processing Backbone
딥러닝을 이용해서 Point cloud를 처리하는 방법론을 공부할 것이다.
<목차>
2-1. PointNet
2-2. PointNet++
2-3. Graph Convolutional Network
2-4. Dynamic Graph CNN
2-5. Kernel Point Convolution
https://arxiv.org/abs/1612.00593
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
Point cloud is an important type of geometric data structure. Due to its irregular format, most researchers transform such data to regular 3D voxel grids or collections of images. This, however, renders data unnecessarily voluminous and causes issues. In t
arxiv.org
2-1. PointNet
- CNN을 Point cloud 처리에 사용하지 않는 이유
-2차원 이미지를 input으로 하는 딥러닝에서 주로 사용하는 CNN은 슬라이딩 윈도우 형태로, 커널을 이동하며 이미지 내의 지역적인 특징을 뽑아내는 식으로 학습을 한다. 이 때 하는게 합성곱Convolution인데 계층적인 연산을 진행하며 얻은 local한 특징을 기반으로, 지속적으로 합성곱을 거치며 좀 더 고차원적이고 Semantic한 특징을 만든다.
-CNN은 하나의 커널을 기반으로 하나의 레이어에서 학습을 하기 때문에 모든 영역에서 weight sharing이 가능.
-2차원 이미지와 같은 구조에서 지역적인 특징 뽑으며 학습하기 좋은 네트워크 구조.
이렇게 이미지를 처리하는 데에 장점만 있는 것 같지만, Point cloud는 비정규적인 구조를 가짐에 주목해야한다. 특히, 포인트 클라우드는 Unordered한 특성과 Permutation invariant한 특성을 갖는다. 앞서 말한 CNN의 슬라이딩 윈도우 형태는 Input의 정형화된 구조를 필요로 하기에 point cloud 처리에 한계를 갖는다.
cf. Permutation invariant: 각 요소가 어떤 순서로 데이터가 불러들여져도 그 형태 등의 특징은 동일한 것. 즉 Permutation invariance란 input data들을 어떤 순서로 받든지 output에는 영향을 끼치지 않아야 함을 말한다.
Permutation invariant한 특성에서 CNN과 sequential 입력이 들어와야 하는 RNN은 구조는 사용에 한계를 갖는다.
- point cloud에 딥러닝 적용하려면?
해결1) 정규적인 형태의 Voxel화를 하거나 각각의 viewpoint에 상응하는 2차원 이미지 집합으로 변형하는 방법 가능
즉 input 자체를 정형화된 구조로 만들어 CNN을 사용하자는 거다. 하지만 여러 view point에 대한 너무 많은 2D 이미지 집합을 만들게 되고, 불필요한 empty space에 대한 표현까지 그대로 가져가기 때문에 비효율적인 연산을 하게 된다.
해결2) Unordered한 3차원 입력을 별도 전처리 없이 직접 사용하자!!!
이게 바로 우리가 공부할 Point Net의 Key contributions이다. 그냥 별도의 전처리 없이 직접 사용해버리자는 것이다. 이를 통해 Classification, Segmentation이 가능해진다.
- PointNet Architecture
- PointNet의 입력: 3D postion, color, surface normal.
즉 point cloud의 3차원 포인트 위치만을 입력으로 갖는다.
- Point Network의 구조: Classification + Segmentation Network

n개의 point가 입력으로 들어가게 되면 input transform, mlp, feature transform, mlp를 거쳐 nx1024의 output이 나오고, 이를 max pooling을 거쳐 1x1024 형태의 global feature vector 형태로 바꾸게 된다.
이 1x1024 형태의 global feature vector를 활용하여 Classification하거나 Segmentation 하게 된다.
cf. 첫 입력이 nx3인 이유는 n개의 point의 3차원 위치 정보이기 때문이다.
cf2. 계속 nx3을 계속 늘리며 feautre를 찾고 max pooling으로 눌러버리는 느낌으로 생각하면 구조가 전체적으로 파악된다.
- PointNet의 input인 Point set의 주요 특징
1) Unordered: 특정 순서를 기반으로 열거된 구조가 아니다.
Data feeding: 최악의 경우 N!개의 엄청나게 많은 input set을 입력으로 요구할 수 있다.
2) Interaction: 전체 포인트가 하나의 shape를 이룬다고 가정하면, 인근 위치의 포인트끼리는 유사한 정보를 가지고 있다.
특성끼리 상호작용을 이용하자는 것이다. 이러한 특성을 활용해 Local to global로 포인트 클라우드의 특성을 봐야 한다.
ex) 토끼 shape의 귀 부분 포인트들은 유사한 정보를 갖는다..
3) Invariance: Transformation이 적용되더라도 객체 자체가 변하지 않는다. ex) 위치 등을 바꿔도 토끼 shape는 토끼다.
Rotation, translation과 같은 변환이 딥러닝 결과물에 영향을 주지 않아야 한다.
- Point Network 구조의 특징
1) Max pooling 특징 정보의 응집 (Symmetric function)
아래 PointNet에서 Unordered한 입력을 다루는 방법 보면 쉽게 이해할 수 있다.
- PointNet에서 Unordered한 입력을 다루는 방법 : 특징 정보의 응집 (! Max-pooling)
앞에서 PointNet 구조와 입력 데이터의 특징에 대해 알아보았다. 정리하자면, Permutation invariance 특성을 갖는 Point cloud를 애써 바꾸려고 하지 말고, 비정형화 상태로 직접 사용하는 것이 해당 네트워크의 핵심 포인트이다. 그러면 이러한 PointNet이 Unordered한 입력을 다루는 방법에 대해 알아보자.
1) 정렬을 통한 접근..... (x)
그냥 정렬해서 순서를 만들어버리면 어떨까? 이는 잘못된 방법이다. 고차원 공간에서는 포인트 데이터에 자그마한 변화를 주는 것에도 안정적인 정렬이 존재할 수 없다. ex) 1대1 맵핑 실패, 원래의 결과를 보장할 수 없다.

2) RNN 활용.... (x)
짧은 길이의 입력에 대해서는 순서에 불변한 출력 값 도출이 상대적으로 잘 되었으나, 매우 많은 양의 입력이 들어오면 순서의 영향을 받았다. 앞서 계속 말했듯이 point cloud는 Permutation invariance 특성을 가지므로 input data들을 어떤 순서로 받든지 output에는 영향을 끼치지 않아야 한다.
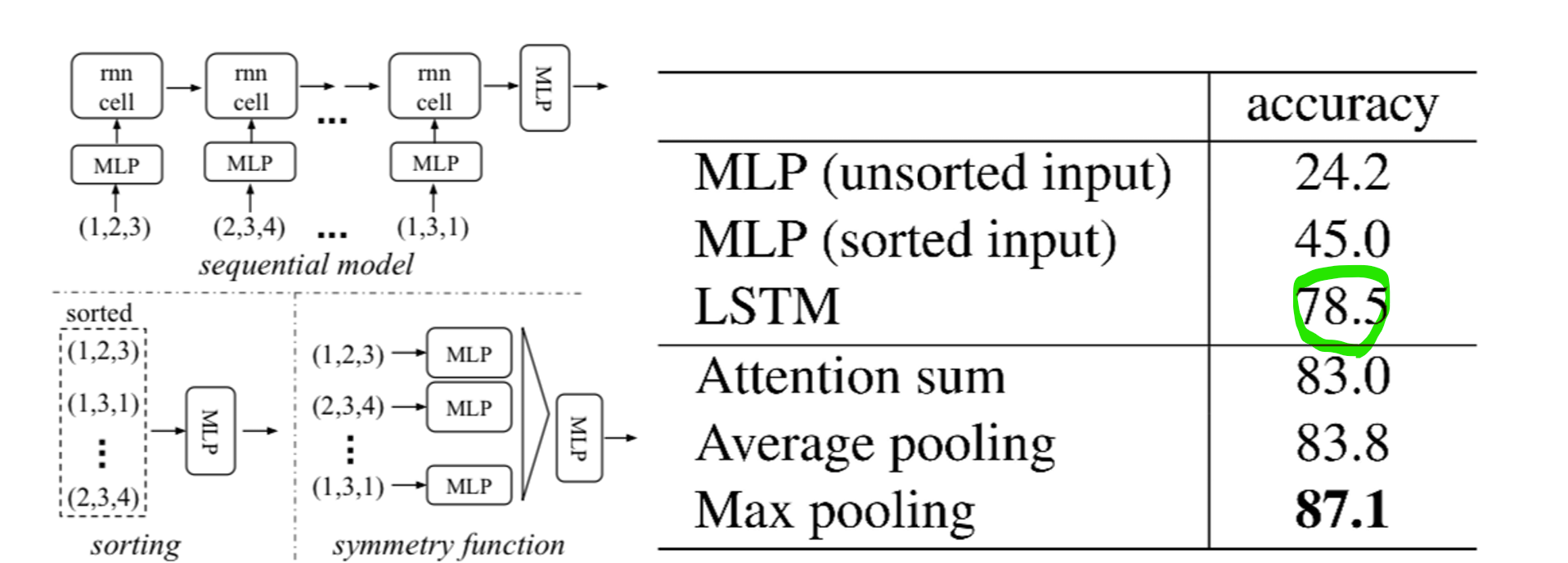
cf. 순서가 없는 데이터인데 데이터가 많을 때, 정렬을 잘 할수록 결과가 좋아지는건.. 좀..
3) Symmetric function!!
포인트 셋을 함수의 입력으로 바로 사용하지 않고, 각각의 포인트에 근사화 적용 후 함수 입력으로 사용. 이 경우에 acc이 가장 높았으며 특히 Max pooling 함수를 사용했을 때, 가장 좋은 결과를 얻었다.


그니까 nx3에서 MLP를 거치며 만들어진 nx1024를 결과를 낼 때 바로 사용하지 말고, 이걸 근사화하여 사용했다는 것이다. 이렇게 했을 때, 가장 좋은 성능을 얻을 수 있었다. 실험 결과를 기반으로 max polling을 사용하는 것이다.
2) Combination 지역적, 전역적 정보의 적절한 조합

중간 layer의 입력값인 nx64에 global feature vector인 1 x 1024를 concatnate한다. 이를 통해 PointNet이 Segmentation 까지 가능해진다. nxm output scores는 m개의 각 클래스에 대한 스코어를 나타낸다.
3) Alignment: 입력 포인트와 포인트 특징을 정렬하는 네트워크 구조 : T-Net의 적용

PonitNet이 아닌 다른 모델을은 특징 추출에 앞서 2차원 이미지 정렬 방법을 사용했다.
PointNet은 Transform을 위한 작은 크기의 T-Net을 제안한다. affine transformation matrix 통해 추정, 이를 입력에 적용하여 transform한다. 쉽게 말하면 기존에는 input을 직접 정렬을 했다면, T-Net을 통해 정렬한다는 것이다.이를 통해 서로 다른 크기의 입력 point cloud를 feature를 한 번 정렬해줄 수 있으며, 불변성에 강한 output을 만들 수 있다.
- T-Net 적용 정리..
기본 목적: 입력 포인트에 적용할 Transformation 추정
확장: Feature에 적용할 Transformation 추정가능. 서로 다른 입력 포인트 클라우드로부터 Feature를 정렬해주는 역할을 할 수 있음.
문제점: 네트워크 후반부에 넣을 수록 더 높은 차원의 Feature를 Transform할 정보를 추정해야 한다. 이 때, 차원이 높아지기에 최적화에 어려움이 생긴다.

문제점 해결: 해당 논문은 정규화를 통해 고차원 Tranformation matrix를 Orthogonal matrix로 바꾸며 최적화를 더 쉽게 만들었다.
- PointNet 이론 분석
위에서 지금까지 PointNet의 input 특성 그리고 네트워크 구조 자체의 특성에 대해 공부했다. 이러한 PointNet 자체의 이론적인 분석을 해보겠다...
PointNet은 PointNet은 안정적으로 포인트 클라우드 shape 정보를 함축하는 feature vector를 뽑아내는 것을 목적으로 한다. 이를 위해 다음과 같은 3가지를 만족해야한다.
1) 작은 섭동에도 출력 값은 변하지 않아야 한다.
2) 잡음이 포함된 입력도 출력 값에 큰 영향을 주지 않아야 한다. ex) 스캐닝, 뷰 이슈..
3) 가림이나 유실 등 데이터 소실이 일부 발생해도 출력 값에 큰 영향을 주지 않아야 한다.
-> 즉 가려지거나, 이동되거나, 약간 안보여도 출력에 큰 영향을 주지 않아야된다. 가려지거나, 잡음이 있는 부분 등에서도 안정적으로 shape에 대한 global한 정보를 잘뽑아야 한다는 게 이 모델의 핵심이다.
- PointNet Experiments 참고..
1) Classification

FC layer와 Max pooling 조합 만으로 SOTA 성능을 도출.
cf) MVCNN은 거의 80개의 view를 projection한 결과물.. 하나의 view만 보면 되는 PointNet이 계산량 등을 고려할 때 더 좋다고 생각할 수 있다.
2) Segmentation

기존 방법론 대비 카테고리 별 평균 IoU가 높게 나옴. ShapeNet데이터셋을 시뮬레이터에 넣고 segment 했을 때, 안정적인 segmentation 결과 도출
3) Semantic segmentation

기존 baseline 모델 대비 높은 성능 향상 보임. 3D object detection으로 연결도 안정적으로 가능할 것이라고 논문에서 제시한다.
4) Robustness test

유실 데이터가 많아도 다른 모델 대비 안정성 저하 정도가 낮았고, 섭동이나 잡음에도 안정성을 최대한 잘 유지함. 안정적으로 shape에 대한 global한 정보를 잘뽑아야 하는 모델의 핵심을 잘 지킴.


이외에도, Model retrieval, Correspondence matching에도 사용할 수 있음을 검증한다.
<결론>
1. 포인트 클라우드를 별도 변환 없이 직접적으로 활용할 수 있는 네트워크 구조 제안
2. Classification, Segmentation 등의 분야에서 활용 가능한 출력 값을 도출할 수 있음
3. 기존 방법 대비 높은 성능 향상을 보임을 실험을 통해 증명
4. 제안한 방법의 이론적 분석을 통한 이점을 증명함
2-2. PointNet++
2-3. Graph Convolutional Network
2-4. Dynamic Graph CNN
2-5. Kernel Point Convolution
'Autonomous Driving > 2. LiDAR Perception' 카테고리의 다른 글
| Ch02. Point Cloud Processing Backbone - 3) Graph Convolutional Network(GCN) (1) | 2024.09.09 |
|---|---|
| Ch02. Point Cloud Processing Backbone - 2) PointNet++ (0) | 2024.09.06 |
| Ch01. LiDAR Data Processing - 3) Open3d, CloudeCompare, LiDAR 레이블링 툴 (2) | 2024.09.05 |
| Ch01. LiDAR Data Processing - 2) ROS1 환경 구성, 데이터셋 (0) | 2024.09.05 |
| Ch01. LiDAR Data Processing - 1) 3D 비전, LiDAR 센서, Point cloud (0) | 2024.09.05 |