DriveLM: Driving with Graph Visual Question Answering [ECCV 2024 Oral]
https://arxiv.org/abs/2312.14150
DriveLM: Driving with Graph Visual Question Answering
We study how vision-language models (VLMs) trained on web-scale data can be integrated into end-to-end driving systems to boost generalization and enable interactivity with human users. While recent approaches adapt VLMs to driving via single-round visual
arxiv.org
0. Abstract

웹 규모 데이터로 학습된 VLM을 E2E 자율주행 시스템에 통합하려는 연구이다. 이를 통해 일반화 능력을 향상시키고, 인간과의 상호작용을 가능하도록 한다.
- Graph VQA Task 제시 # key insight
기존의 자율주행 연구들은 단일 질문-답변 VQA 형태로 VLM을 자율주행에 적용했지만, 인간 운전자는 여러 단계에 걸쳐 추론을 진행한다. 중요한 객체를 먼저 인식하고, 상호 작용을 추정한 다음 행동을 취하게 된다.
기존 연구들과 달리 인간의 추론 과정을 모방하여 해당 연구는 perception, prediction, planning의 단계를 따르는 그래프 기반으로 추론 구조를 모델링한다.
이를 위해 nuScenes 및 CARLA 기반의 데이터셋과 베이스라인 모델 DriveLM-Agent를 도입해 설명 가능한 일반화된 자율주행을 실현하며 경쟁력 있는 성능을 보인다. 특히 보지 못한 센서 구성에서도 학습 없이zero-shot 강한 일반화 성능을 보인다. 질문별 분석 결과, 그래프 구조 내에서 예측 및 계획 단계의 풍부한 질문-답변 주석이 성능 향상의 원인임을 확인했다.
1. Introduction
- 기존 자율주행 시스템의 한계
현재의 자율주행 시스템은 여전히 중요한 기능들이 부족하다. 다음과 같은 요구사항이 존재한다.
1) Generalization
> 처음보는 상황이나 낯선 센서 구성도 잘 처리해야한다.
2) Interaction
> 인간과 자율주행 모델이 상호작용할 수 있어야한다. 이는 EU의 설명 가능성 규정에서도 강조된다.
3) 인간과의 차이 ***
> 현재의 자율주행 모델들은 기하학적으로 정밀한 BEV 표현에 기반하여 운전을 한다. 하지만 인간은 객체 중심의 인식, 예측, 계획을 암묵적으로 수행하게 된다. 중요한 객체를 파악하고, 위치가 어디 있는지 추정한 후, 어떻게 움직일지 추론하고, 이를 바탕으로 운전 행동을 결정하게 된다.
- VLM의 발전 및 접목
여러 장점들을 가진 Vision-Language Model이 빠르게 발전하고 있다. VLM을 자율주행에 적용하면 다음과 같이 위에서 제시된 요구 사항을 해결할 수 있다.
1) 일반화 성능 증가 # Generalization
> 인터넷 수준의 방대한 데이터로부터 세상에 대한 기본적인 이해를 갖고 있어, 자율주행에서의 계획 수립에 필요한 일반화에 도움을 줄 가능성이 존재한다. 이러한 가능성은 이미 단순한 로봇 작업에서 달성된 바 있다.
2) 사람이 이해하기 쉬운 상호작용 가능 # Interaction
> VLM은 언어 표현을 입력과 출력으로 사용하기 때문에, 기존의 바운딩 박스나 궤적 기반 방법과 달리 사람이 이해하기 쉬운 상호작용이 가능하다.
3) 논리적으로 연결된 여러 단계에 걸쳐 결정을 내림 # 인간과 비슷해짐
> 여러 단계를 나눠 추론하더라도, VLM은 엔드 투 엔드로 미분 가능한 구조이기 때문에, 이는 자율주행에 매우 적합한 특성이다.
# End-to-End Differentiable
- VLM을 자율주행 시스템에 적용하려는 최근의 연구 및 한계
VLM을 자율주행 시스템에 적용하려는 최근의 연구들은 크게 두 가지 범주로 나눌 수 있다.
연구1) Scene-level Visual Question Answering (VQA)
> 운전 행동을 1~2개의 이유로 설명하는 과제이다.
ex) 차가 오른쪽 차선으로 이동하는 이유는 그것이 안전하기 때문이다.
연구2) Single object-level Visual Question Answering (VQA)
> ' 하나의 객체'에 대해 자율차가 어떻게 반응하는지를 “what-which-where-how-why” 형태의 질문 체인으로 구성한다.
ex) 자율차가 멈춘 이유는, 앞 교차로를 흰 셔츠를 입은 보행자가 건너고 있고, 그 보행자와 충돌하고 싶지 않기 때문이다.
하지만 이 두 방식 모두 여러 객체를 다단계로 추론하는 인간의 P1–3 추론 과정을 모방할 적절한 Proxy Task가 아니다.
- 해당 연구가 제시하는 3가지
해당 연구는 새로운 Task Graph VQA와 이에 대응하는 데이터셋 그리고 baseline model architecture를 제안한다.
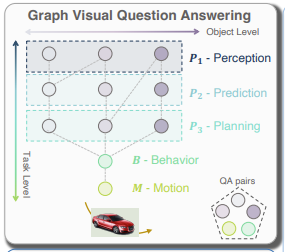
1) 인간의 추론 과정을 모방한 새로운 Task: Graph Visual Question Answering (GVQA)
> 사람의 추론 과정을 모방하여 자율주행의 인식, 예측, 계획 추론 과정을 질문-답변(QA) 쌍의 방향 그래프로 구성하는 과제
> 기존 VQA와 달리 GVQA는 QA 간의 논리적 의존성이 존재하여 응답 과정을 안내할 수 있다. 행동, 주행 계획 질문을 포함하며, 전용 평가 지표도 제공한다.
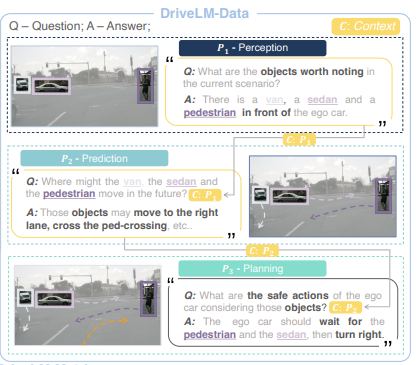
2) Datasets: DriveLM-nuScenes and DriveLM-CARLA
> 주석이 달린 QA들로 구성되며, 이들을 그래프 형태로 배치하여 이미지와 주행 행동을 논리적으로 연결함. 기존 벤치마크들과 비교해 프레임당 훨씬 많은 텍스트 주석을 제공한다.
> PDM-Lite라는 CARLA 리더보드 2.0을 위한 최초의 규칙 기반 전문가 알고리즘도 구축함.
> 학습 데이터셋과 함께, 제로샷 일반화 성능을 평가하기 위한 도전적인 테스트 데이터도 구성

3) Baseline: DriveLM-Agent
> 어떤 VLM에도 적용 가능한 trajectory tokenizer를 사용하며, 논리적 의존성을 맥락context으로 입력하는 그래프 프롬프팅 방식과 결합된다. 이는 결과적으로 VLM을 E2E 자율주행에 효과적으로 재활용할 수 있는 간단한 방법론이다.

- Experiments & Results
DriveLM에서의 GVQA는 도전적인 과제로, 논리 의존성의 정교한 모델링이 요구되지만, DriveLM-Agent는 과제 특화 없이도 오픈 루프 환경에서 SOTA 자율주행 모델들과 경쟁력을 보인다. 그래프 구조 덕분에 제로샷 일반화 성능이 향상되어 nuScenes로 학습한 모델이 Waymo 데이터에도 잘 대응하였고, 질문별 분석에서는 예측·계획 단계의 QA가 최종 주행 결정에 가장 크게 기여함을 확인하였다. 이를 통해 GVQA는 높은 일반화 능력을 갖춘 자율주행 에이전트 구축에 유망한 접근임을 시사한다.
2. DriveLM: Task, Data, Metrics
DriveLM은 인간 운전자의 논리적 의사결정 흐름을 모방하기 위해 GVQA를 핵심 과제로 제안하고, 이를 기반으로 한 데이터셋 DriveLM-Data과 평가 지표 DriveLM-Metrics를 통해 다양한 자율주행 방법의 비교 및 연구를 가능하게 한다.
이 방향의 추가 연구를 장려하기 위해, 공식 평가 서버와 공개 리더보드를 구축하여 다양한 방법을 비교 평가하고, 언어 모델과 자율주행의 융합에 대한 통찰을 더 얻을 수 있도록 할 예정이라고 한다...
- DriveLM-Task: GVQA ((2.1))
하나의 이미지 프레임에 대한 모든 질문-응답(QA) 쌍을 하나의 방향성 비순환 그래프 Directed acyclic graph((DAG))로 표현한다.

그래프 G=((V,E))는 꼭짓점 집합 를 가지며, 각 꼭짓점은 시나리오 내 하나 이상의 핵심 객체와 연관된 QA 쌍 v=(를 나타낸다.
GVQA와 일반적인 VQA의 핵심 차이점은, GVQA의 QA 쌍은 논리적 의존성을 가지며, 이것을 꼭짓점 간의 Edges으로 표현한다는 것이다.