DriVLMe: Enhancing LLM-based Autonomous Driving Agents with Embodied and Social Experiences
https://arxiv.org/abs/2406.03008
DriVLMe: Enhancing LLM-based Autonomous Driving Agents with Embodied and Social Experiences
Recent advancements in foundation models (FMs) have unlocked new prospects in autonomous driving, yet the experimental settings of these studies are preliminary, over-simplified, and fail to capture the complexity of real-world driving scenarios in human e
arxiv.org
0. Abstract
최근 LLM과 같은 pretrain된 foundation model((FMs))의 발전으로 자율주행 분야에는 새로운 가능성이 열리고 있다.
하지만 이러한 연구들의 실험 환경은 아직도 초기 단계이며, 지나치게 단순화되어 있어 인간 환경에서의 실제 주행 시나리오의 복잡성을 반영하지 못한다고 해당 논문는 지적한다. 관련하여 다음과 같은 도전 과제가 존재한다.
- FM 기반 에이전트가 free-form dialogue를 사용하며, long-horizon navigation tasks를 수행할 수 있는가
- 환경 동적 변화나 task가 바뀔 때 발생하는 예상치 못한 상황을 처리할 수 있는가
해당 연구는 FM의 역량과 한계를 탐색하기 위해 video-language model 한 에이전트 DriVLMe를 소개한다. 해당 모델은 인간과 자율 주행 차량 간의 자연스럽고 효과적인 의사소통을 지원하며, 차량이 주변 환경을 인식하고 내비게이션할 수 있도록 돕는다.
해당 모델을 Instruction Tuning하기 위한 embodied experiences, social experiences를 개발하였으며, open-loop 벤치마크와 closed-loop 인간 연구 모두 경쟁력 있는 성능을 보였다. 하지만 몇 가지 도전 과제를 다시 한 번 제시한다.
- 허용할 수 없는 수준의 추론 시간
- 불균형한 학습 데이터
- 제한적인 시각적 이해
- 다중 턴 상호작용의 어려움
- 봇 경험에서 나온 단순화된 언어 생성
- 환경 변화 및 작업 변경과 같은 돌발 상황에 대한 대응 부족
1. Introduction
자율 주행이 놀라운 발전을 이루며 자율주행 에이전트 AD agents가 우리의 일상생활에 점점 더 도입됨에 따라, 인간-에이전트 간의 효과적인 대화 및 협업을 가능하게 하는 기술이 중요해지고 있다.
특히, 자연어 대화를 통해 인간과 소통하는 능력은
승객 안전 보장,
예상치 못한 상황에서의 복구,
신뢰성(trustworthiness) 확보,
전반적인 주행 경험 향상
등에서 중요한 역할을 한다
- 인간-에이전트 대화 및 협업 기술
1) 전통적인 자율주행 시스템 및 차량 대화 시스템
규칙 기반(rule-based) 접근 방식이 사용되어 사용자의 지시를 해석하고 적절한 응답을 생성. 이러한 시스템은 자연어의 복잡성과 변동성을 처리하는 데 어려움을 겪으며, 기능이 제한되고 최적의 성능을 발휘하지 못하는 경우가 많다
2) 최근의 방식: learning-based approaches
데이터 기반(data-driven) 학습 기반 접근 방식learning-based approaches 으로 패러다임이 변화하고 있으며, 이러한 방식은 자연어 해석력 language-based interpretability을 제공하고, 단기short-horizon 작업에서 유망한 결과를 보여준다.
- 파운데이션 모델((FMs))의 적용 및 한계
파운데이션 모델, 특히 LLM의 발전은 새로운 기회를 열어주고 있으며, 자율 주행 분야에서도 FM의 가능성을 보여주는 연구가 점점 증가하고 있다.
LLM은 다음과 같은 능력을 보여준다
단계별(step-by-step) 추론 수행
멀티모달 데이터(multimodal data) 이해
체화된 경험(embodied experiences)으로부터 학습
외부 도구(external tools) 활용
하지만 이러한 연구들의 실험 환경은 여전히 초기 단계이며 단순화되어 있어, 실제 인간 환경에서의 운전 시나리오와 비교하면 제한이다. 공통적으로 장기적인 내비게이션 작업을 처리하는 능력이 부족하며, 단일 회차((single turn)) 상호작용에서 개별 명령을 따르는 데만 초점을 맞추고 있으며, 자유로운 형태의 대화 Free-form dialogue 그리고 예상하지 못한 상황에 대한 대응이 부족하다.
이러한 맥락을 모델링하지 않으면, 묘한 대화를 이해하지 못하고 인간-차량 상호작용에서 적절한 응답을 제공하는 데 실패할 가능성이 크다.
- 파운데이션 모델의 한계와 도전 과제 탐색
위에서 언급한 파운데이션 모델 FM의 한계와 도전 과제를 탐색하기 위해, 비디오-언어 모델video-language model에 기반한 새로운 자율 주행(AD) 에이전트 DriVLMe를 소개한다. 해당 에이전트는 주변 환경을 인식하고 내비게이션을 수행하는 자율 차량과 인간 간의 자연스럽고 효과적인 의사소통을 가능하게 한다.
해당 연구는 world model 및 agent model로서의 언어 모델 백엔드 language model backend 를 강화하는 것을 목표로 한다.

이전 연구들이 비대화형 데이터셋을 활용한 open-loop 평가에 집중한 반면, 본 연구는 CARLA 시뮬레이터를 활용한 open-loop 및 closed-loop 평가를 모두 수행하였다.
실험 결과, DriVLMe는 SDN 벤치마크에서 기존 베이스라인을 압도적으로 능가했으며, LLM-증강 데이터로 학습된 모델과도 경쟁 가능한 성능을 보였다. 그러나, 추론 속도 문제, 훈련 데이터 불균형, 이미지 해상도 한계 등 여러 제약이 존재하며,
특히 다중 턴 상호작용 및 로봇 경험 기반 언어 생성이 주요 도전 과제로 남아 있다.
본 연구는 FM을 활용한 자율 주행 시스템의 강점과 한계를 정리하고, 향후 개선이 필요한 영역을 제시하는 데 의의가 있다.
2. Related Work
미완성..
3. Dorothie & Situated Dialogue Navigation
해당 논문은 CARLA 시뮬레이터에서 실험을 설정했으며, 이를 기반으로 구축된 DOROTHIE 프레임워크를 사용한다.
https://arxiv.org/abs/2210.12511
해당 프레임워크는 인간-에이전트 사이의 대화를 지원하며, 다양한 형태의 예외 상황을 처리할 수 있다. 또한 Situated Dialogue Navigation((SDN)) 벤치마크에서 문제 정의와 데이터를 채택하였다.
- SDN 벤치마크 Overview ((3.1))
해당 벤치마크는 주변 환경 인지 및 대화 기록에 따라 대화 응답과 물리적 네비게이션 행동을 생성하는 에이전트의 능력을 평가하기 위해 설계되었다. 8,000개 이상의 발화와 18.7 시간 분량의 인간-인간 상호작용 데이터를 Wizard-of-Oz(WoZ) 연구에서 수집하였다.

WoZ 연구에서는 인간 참가자가 자율주행 에이전트라고 믿는 시스템과 상호작용하며 다양한 내비게이션 작업을 수행한다. 인간 참가자는 반대편이 자율주행 에이전트인줄 알았지만 사실은 데이터를 수집하려는 연구원인 것이다...! 그래서 사람-사람 데이터이다.
데이터를 생성하는 중에 즉석에서 예상치 못한 상황을 만드는 adversarial wizard도 존재한다. 즉 연구원이 갑자기 이상한 말을 하거나, 이상한 행동을 한다는 것이다. 이러한 예상치 못한 상황이 생겼을 때 인간의 대처를 데이터에 포함한다면, 예상치 못한 상황에서 학습된 모델이 어떻게 대응하는지 벤치마크할 수 있을 것이다.
ex) 언어 지시를 사용하거나 도로 환경을 조작하여 환경의 동적 요소뿐만 아니라 현재 목표 및 계획을 변경
참여자 = 반대편이 자율주행 Agent(AI)라고 믿고 대화하고 있는 사람
Wizard = 우리가 목표로 하는 AI 모델(Agent)의 이상적인 행동을 보여주는 인간 연구원, 반대편 속이고 있음
Agent = Wizard의 행동을 학습하고 모방해야 하는 AI
- Problem Defintions ((3.2))
시간 t에서 Agent는 센서 데이터, 맵, 행동 기록과 같은 지각 정보와 인간의 언어 입력을 받는다. 이를 정리하면 다음과 같다.

1) Map knowledge
>> 그래프 구조의 지형 정보 M, 거리 이름 목록 {str_i}, 랜드마크 위치 {lm_i}
2) Perceptual history
>> 1인칭 카메라로 촬영된 RGB 이미지 시퀀스 V={V0,V1,…,Vt−1}, 1초당 10 프레임 즉 10Hz
3) Dialogue history
>> 인간과 에이전트간의 대화 기록
ex) 오른쪽으로 가 주차장을 찾아 -> 우회전을 합니다. 주차장을 찾았습니다.
4) Action history
>> 이전에 수행한 Action들의 시퀀스 At={a0,a1,…,at−1}, 각 행동 a는 가속, 회전 등을 포함하는 물리적 행동과 속도 회전 각도를 포함하는 Argument의 튜플 형태이다.
ex) 시간 3에 속도를 10km/h 올렸다면, a_3 = <"Acclerate", 10>
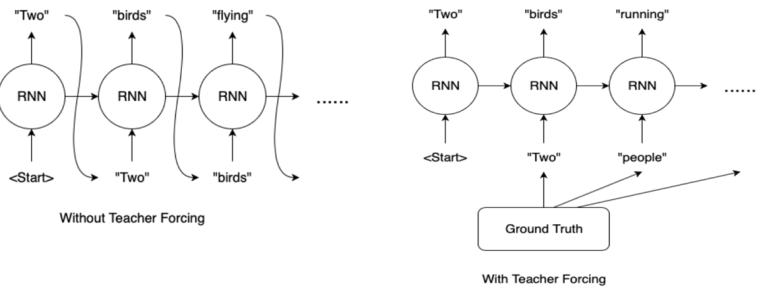
이러한 데이터를 받은 Agent의 목표는 인간 대화의 지시를 따라 지도상의 랜드마크를 순차적으로 네비게이션하는 것이다. 미래의 대화 일관성과 예상치 못한 사건을 고려하기 위하여 해당 작업은 Teacher-Forcing 방식으로 정의된다. 모델이 예측한 행동이 아닌 실제 수행된 행동 이력 At={a0,a1,…,at−1}를 제공받아 학습하게 된다. 이렇게 학습된 모델은 Woz 실험에서 AI역할을 하던 연구원 즉 wizard의 행동 및 대화 결정과 비교하여 평가될 것이다
cf1. 네비게이션: 주어진 목적지를 향해 경로를 찾아 이동하는 것.
cf2. Teacher-forcing 방법에 대해 아래 간단하게 정리해놨다.
이 과정에서 특히 두 가지 하위 문제를 고려한다.
고려사항 1) The Dialogue Response for Navigation ((RfN)) task # 자연스러운 문장 만들기
>> 운전 관련 대화에서 적절한 응답을 생성하는 에이전트의 성능을 평가한다.
Wizard 즉 Agent인 척하는 연구원의 대화 응답을 학습하고, 비슷한 맥락에서 스스로 응답을 생성하도록 한다. 이를 잘 하는지 평가한다는 것이다.
✔ Human (운전자): "우리 여기서 우회전할까요?"
✔ Wizard (AI 역할을 하는 인간 연구원): "네, 신호에 맞춰 우회전하세요."
✔ Agent (학습된 AI, 예측된 응답): "네, 우회전하겠습니다."
wizard와 학습된 에이전트의 응답이 비슷하니까 이런 경우 학습이 잘 된 것이다.
고려사항 2) The Navigation from Dialogue ((NfD)) task.
>> 대화를 통해 인간의 지시를 따르는 에이전트의 성능을 평가
Wizard가 물리적 행동 을 결정했다면, 이와 비슷한 결정을 내릴 수 있는지 모델을 평가한다는 것이다.
✔ Human (운전자): "속도를 좀 더 올릴까요?"
✔ Wizard (실제 AI 역할을 하는 인간 연구원): "네, 속도를 10km/h 올리겠습니다."
✔ AI Agent (학습된 AI, 예측된 행동): 𝑎3 = ⟨"Accelerate",10⟩
wizard의 학습된 에이전트의 행동과 같으니까 이런 경우가 학습이 잘 된거지
이러한 두 개의 고려사항을 해결해 나갈 것이다.
4. Method
- Model Architecture ((4.1))

해당 연구가 제시하는 DriVLMe는 세 가지 주요 구성요소로 이루어진 large video-language model이다.
이 세 가지 구성요소에 대해 알아볼 것이다.
- 구성요소 1 - Video Tokenizer # Vision Token를 만드는 과정

과정1) 비디오 시퀀스 구성
시간 t에서의 Perceptual history는 RGB 이미지 시퀀스 V={V0,V1,…,Vt−1}이다.
사용하는 SDN 벤치마크는 장기적인 시퀀스를 갖고 있기에 최대 윈도우 크기 T_max = 40, 시간 간격 Δt=2를 설정하여 샘플링, 다음과 같은 비디오 시퀀스를 구성할 수있다.
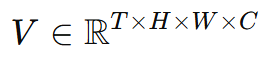
과정2) feature map 추출
이렇게 구성한 비디오 프레임 (V_i)에 대해, pre-trained CLIP ViT-L/14 encoder를 사용하여 feature map f를 추출한다.

cf. p를 vit의 patch size라고 하자. 이를 통해 H, W를 쪼갤 것이므로 h = H/p ,w = W/p. D는 CLIP 인코터의 특징 차원.
과정3) Average Pooling
이러한 feature map을 Average Pooling하여 두 가지 표현을 얻는다.

과정4) Concatenating
이제, 두 개의 임베딩을 결합하여 최종적인 비디오 표현을 얻는다.

과정5) Linear Projection Layer : g
비디오 특징을 언어 모델이 이해할 수 있는 형태로 변환하기 위해, 임베딩 v을 언어 디코더의 임베딩 공간으로 투영. 해당 벡터가 비전 토큰이다. K가 바로 최종 임베딩 차원이다.

- 구성 요소2 - LLM Backbone

LLM Decoder는 입력된 비디오를 처리하고, 대화 지시 Dialogue Instructions를 저수준 의사 결정 Lower-Level Decisions으로 변환하는 핵심 모듈. 즉 인간의 자연어 지시를 받아, 실제 행동으로 변환한다. Vicuna-7B를 디코더로 채택함.

환경 이해를 위한 Planning Framework를 도입하여 agent가 주행 계획을 잘 세울 수 있도록 유도한다.
환경을 묘사하는 프롬프트와 다음 주행 행동을 선택하고 응답을 생성하는 프롬프트를 주는 듯 하다..
- 구성 요소3 - Route Planning Module

장기적인 목표 long-horizon goals를 위한 Symbolic Planning을 가능하게 하기 위해 Route Planner를 도입하여 지도 M의 그래프 지식을 DriVLMe에 통합한다.
Symbolic Planning: 지도 내 랜드마크를 기호(symbol)처럼 활용하는 방식, 해당 Agent의 목표를 다시 생각해보자...
플래너는 M에 포함된 목표 랜드마크 정보 lm∈{lmi} 와 에이전트의 현재 위치 l을 입력으로 받는다. 이후 에이전트에서 목표 랜드마크까지 최단 경로를 표현하는 각 교차로에서의 회전 방향 리스트를 출력한다. 이는 plan(랜드마크) 함수로 실행할 수 있다.
ex) [left, straight, right, .....], 각 방향 지시는 left, right, straight, uturn 중 하나이다.
- Instruction Tuning ***
1) 비디오 데이터 학습 Domain Video Instruction Tuning → LLM이 자율주행 관련 비디오 데이터를 이해하도록 조정.
2) 대화 및 계획 학습 Social Instruction Tuning → 인간과 자연스럽게 대화하고, 목표에 맞게 경로 계획을 조정하도록 학습.
3) 시뮬레이터 환경 학습 Embodied Instruction Tuning → 센서 데이터를 기반으로 AI가 실제 환경을 분석하고 대응하도록 학습.