DriveGPT4: Interpretable End-to-end Autonomous Driving via Large Language Model
https://arxiv.org/abs/2310.01412
DriveGPT4: Interpretable End-to-end Autonomous Driving via Large Language Model
Multimodal large language models (MLLMs) have emerged as a prominent area of interest within the research community, given their proficiency in handling and reasoning with non-textual data, including images and videos. This study seeks to extend the applic
arxiv.org
0. Abstract
해당 연구는 멀티모달 대형 언어 모델((MLLMs))을 자율주행 영역으로 확장하고자 하는 새로운 해석 가능한 LLM 기반 End-to-end autonomous driving system을 소개하고자 한다.
해당 시스템인 DriveGPT4는 multi-frame 비디오 입력과 텍스트 질의 입력를 처리하여 차량 동작을 해석하고, 관련 추론, 사용자의 다양한 질문에 대한 응답 능력을 갖는다. 추가적으로 end to end 방식으로 속도, 방향과 같은 low-level 수준의 차량 제어 신호를 예측할 수 있다.
이러한 기능들은 자율주행 응용에 특화된 맞춤형 instruction tuning dataset과 mix-finetuning training strategy을 통해 구현될 수 있었다.
https://tonyxuqaq.github.io/projects/DriveGPT4/
DriveGPT4
Abstract Multimodal large language models (MLLMs) have emerged as a prominent area of interest within the research community, given their proficiency in handling and reasoning with non-textual data, including images and videos. This study seeks to extend t
tonyxuqaq.github.io
1. Introduction
- Data-driven learning-based, End to End autonomous driving system 도입과 문제점
지난 10년간 자율주행 기술은 학계와 산업에서 눈부신 성장을 이루며 항구, 창고, 도심 등 다양한 환경에 상업적으로 성공적으로 적용되고 있다. 하지만 기존 자율주행 시스템은 인지, 계획, 제어 등 모듈형 설계를 기반으로 규칙 기반 방법으로 구현되지만, 예기치 못한 상황에서는 한계를 드러낸다. 이를 해결하기 위해 데이터 기반 학습과 전체 시스템을 더 잘 통합하고 최적화하기 위한 End to End 시스템을 도입하며 더욱 지능적이고 통합된 시스템을 구현하려 하고 있다.

그럼에도 불구하고 엔드 투 엔드 학습 기반 자율주행 시스템은 블랙박스처럼 작동하여, 시스템에서 생성된 결정을 인간이 해석하거나 이해할 수 없으며 이는 중요한 윤리적 및 법적 문제를 초래하고 상업적 자율주행 시스템 개발을 제한하게 된다.
cf. End to End System으로 자율주행을 구현하면 이게 왜 이렇게 움직이는지 해석이 불가능하니까 이를 믿을 수 없다는거다. 만약 사고가 발생하면 이게 왜 났는지 해석할 수 없을 것이다.
- Explainable autonomous driving
최근 몇 년간 위에서 언급한 End to End 자율주행의 단점을 해결하고자 하는 설명 가능한((explainable)) 자율 주행이 점점 많은 관심을 받고 있다.
- 설명 가능한 자율주행을 연구한 선행 연구들
[11] T. Deruyttere, S. Vandenhende, D. Grujicic, L. Van Gool, and M. F.
Moens, “Talk2car: Taking control of your self-driving car,” in EMNLPIJCNLP, 2019.
[12] J. Kim, T. Misu, Y.-T. Chen, A. Tawari, and J. Canny, “Grounding
human-to-vehicle advice for self-driving vehicles,” in CVPR, 2019.
[13] S. Atakishiyev, M. Salameh, H. Yao, and R. Goebel, “Explainable
artificial intelligence for autonomous driving: A comprehensive overview
and field guide for future research directions,” IEEE Access, 2024.
[14] B. Jin, X. Liu, Y. Zheng, P. Li, H. Zhao, T. Zhang, Y. Zheng, G. Zhou,
and J. Liu, “Adapt: Action-aware driving caption transformer,” in ICRA,
2023.
[15] S. Malla, C. Choi, I. Dwivedi, J. H. Choi, and J. Li, “Drama: Joint risk
localization and captioning in driving,” in WACV, 2023.
이러한 연구들은 자율주행 차량 데이터와 언어 쌍을 포함하는 대규모 데이터 셋을 개발한다. 이 데이터셋을 통해 BERT, GPT와 같은 언어 모델을 학습시켜 센서 데이터의 입력을 기반으로 자연어를 생성하도록 한다.
더 나아가 Chatgpt, LLaMA와 같은 대형 언어 모델((LLMs))이 등장으로, LLM이 방대한 일반 지식을 보유하게 되고, 고유한 추론 능력으로 인해 low-level 차량 제어를 더 잘 분석하고 생성할 잠재력을 갖기에 자율주행 시스템의 해석 가능성에 긍정적인 영향을 주고 있다.
- DriveGPT4
위 연구들이 달성되기 위해서는 LLM은 이미지나 비디오 같은 multimodal data를 잘 이해해야함은 자명하다. 이미지, 오디오, 비디오, 제어 등 다양한 공간의 멀티모달 데이터 입력을 텍스트 도메인으로 변환하여 LLM이 이를 텍스트로 이해하고 처리할 수 있도록 제안하는 Multimodal LLM((MLLMs))를 사용하게 된다.
본 연구에서는 멀티모달 대형 언어 모델((MLLMs))을 활용한 해석 가능한 엔드 투 엔드 자율주행 시스템인 DriveGPT4를 소개한다. DriveGPT4는 전방 단안 RGB 카메라로 촬영한 비디오 시퀀스를 입력으로 받아 다음 단계의 제어 신호(예: 차량 속도 및 회전 각도)를 예측하게 되고, 동시에 사용자는 DriveGPT4와 대화할 수 있으며 차량의 동작을 설명받을 수 있게된다. -> 설명 가능한 자율주행 시스템
- Contributions ***
1) E2E 자율주행을 위한 새로운 멀티모달 LLM인 DriveGPT4를 제시
생성된 데이터셋으로 Mix-finetuning된 DriveGPT4는 멀티모달 입력 데이터를 처리하고 텍스트 응답과 저수준 제어 신호를 생성할 수 있다.
2) 해석 가능한 자율주행을 위한 새로운 시각적 지시 조정 데이터셋을 개발
ChatGPT의 도움으로 해석 가능한 자율주행을 위한 새로운 시각적 지시 조정 데이터셋을 개발, DriveGPT4의 성능을 향상.
3) BDD-X 데이터셋에서 모든 방법을 평가
DriveGPT4는 모든 기준선을 능가하여 그 효과를 입증.
2. Related Works
1) End-to-End Autonomous Driving
엔드 투 엔드 자율주행은 시각적 입력을 기반으로 차량 경로와 저수준 제어 신호를 직접 예측하는 방식이다. 초기 연구에서는 단안 이미지를 입력으로 받아 합성곱 신경망(CNN)을 훈련시켜 차량을 제어했다.
이후, 모듈 출력값을 토큰화하여 시스템을 통합하는 방식이 등장했으며, 이를 통해 더 강력하고 안정적인 제어 효과를 얻었다. 하지만 이러한 방식은 해석 가능성이 부족하다는 단점이 있어 신뢰성과 상업화 가능성에 한계가 있다.
2) Interpretable Autonomous Driving
학습 기반 자율주행 시스템의 블랙박스 문제를 해결하기 위해 여러 접근이 시도되었다. 일부 연구는 시각화를 통해 차량의 행동을 설명하려 했지만, 시각적 맵은 비전문가가 이해하기 어려운 단점이 있다.
이를 보완하기 위해 언어 모델을 활용하여 차량 행동, 행동 이유, 주변 객체 설명, 잠재적 위험 등을 자연어로 표현하는 방법도 제안되었다. 하지만 작은 언어 모델의 용량 제한으로 인해 이러한 접근은 미리 정의된 질문에만 답변할 수 있는 경직된 형태로 남아있다. 이는 실제 응용에서 제약으로 작용한다.
3) Multimodal Large Language Models (LLMs)
멀티모달 LLM은 텍스트뿐만 아니라 이미지나 비디오 같은 다양한 입력 데이터를 처리할 수 있는 모델이다. PaLM, LLaMA, Vicuna와 같은 사전 학습된 LLM을 기반으로 다양한 작업에서 활용되고 있으며, Blip은 Q-former를 활용해 멀티모달 데이터를 텍스트 공간으로 변환한다. 이러한 모델은 이미지 및 비디오 이해, 의료 진단, 임베디드 AI 등 다양한 분야에서 사용된다.
DriveGPT4는 멀티모달 LLM의 발전에서 영감을 받아 비디오 데이터를 이해하고 차량 제어 신호를 예측하는 데 초점을 맞춘다. 기존의 DriveLikeHuman은 단순 시뮬레이션 장면에서만 동작하며, NuPrompt는 객체 추적에 초점을 맞추지만 엔드 투 엔드 주행과 차량 행동 추론을 고려하지 않는다. DriveLM은 주행 장면 이해를 위한 대규모 벤치마크로 활용되지만, DriveGPT4는 이보다 한 단계 더 나아가 해석 가능성과 제어 성능을 결합하려는 시도를 한다.
3. DATA Generation
- BDD-X Dataset

1) 데이터 구성: 약 20,000개의 비디오 샘플 = 16,803((train)) + 2,123((test))
한 비디오 클립 안에는 8개의 이미지가 존재하며, 각 프레임에 대한 차량 속도와 회전 각도와 같은 i) 제어 신호 포함. 또한 각 비디오 클립에 대한 ii) 차량 행동 설명 및 iii) 행동 이유를 상세히 설명하는 텍스트 주석이 포함되어 있음.
2) BDD-X question-answerings.
학습에 사용한 BDD-X 데이터는 한 비디오 클립을 구성하는 각 8개의 프레임에 대한 i) 제어 신호 그리고 비디오 클립에 대한 ii) 차량 행동 설명, iii) 행동 이유 라벨이 존재한다.
이러한 데이터로 LLM을 학습 시키려면 질문-응답((Q-A)) 쌍이 필요하며, 3개의 라벨이 존재하므로 이에 맞는 3개 유형의 질문-응답 쌍이 필요하게 된다. 과적합을 피하기 위해 한 질문에 대한 동의 표현을 다수 포함시켜 질문을 만들고, 이에 대한 답으로 BDD-X 데이터의 라벨을 사용하게 된다. 사용된 질문 유형은 다음과 같다.
- (Q_a): 차량 행동 설명 질문, 현재 차량 동작은 무엇인가요? 에 대한 비슷한 질문들이 포함되어 있음.
- (Q_j): 차량 행동 이유 질문, 왜 이 차량이 이렇게 행동하나요? 에 대한 비슷한 질문 포함.
- (Q_c): 제어 신호 질문, 다음 프레임에서 차량의 속도와 회전 각도를 예측하라와 비슷한 동의 질문 포함.
위 질문을 만들고, 데이터 라벨과 합쳐 학습 데이터셋을 생성하게 된다. 이를 통해 LLM은 차량 행동을 예측하고 해석하는 것을 동시에 학습할 수 있게 된다.
-> 데이터셋의 한계: 하지만 이러한 QA 쌍은 고정되고 경직된 내용을 갖게 되기에 데이터 다양성 부족으로 모델 성능에 부정적인 영향을 줄 수 있다.
3) Additional QAs generated by ChatGPT

기존의 경직된 데이터 셋은 정해진 질문만 처리할 수 있기 때문에 실질적인 대화 인터페이스로는 적합하지 않다. 즉 BDD-X만으로는 해석 가능한 자율주행의 요구를 충족하기에 충분하지 않다.
이를 위해서 GPT/GPT4를 활용하여 Instruction tuning을 진행, 추가적인 Q-A 데이터를 생성한다. YOLOv8으로 객체 감지를 수행하고, 바운딩 박스, 캡션, 제어 신호 데이터를 ChatGPT에 제공하여 더 풍부한 대화 데이터를 생성하여 최종적으로 56,000개의 비디오-텍스트 명령 데이터를 수집하여 자율주행에 특화된 데이터셋을 구축했다.
4. DriveGPT4

- Model Architecture
DriveGPT4는 비디오와 텍스트를 포함한 다양한 입력 유형을 처리할 수 있는 다목적 멀티모달 LLM이다.
비디오는 고정된 수의 이미지로 균일하게 샘플링되며, Valley 기반의 비디오 토크나이저를 사용해 비디오 프레임을 텍스트 도메인 토큰으로 변환, 생성된 모든 토큰들은 연결 된 후 LLM에 입력되기 된다.
예측된 토큰이 생성되면 De-Tokenizer가 이를 해독하여 고정 형식의 예측 신호를 포함하는 인간 언어로 복원한다.

- Video Tokenizer
과정은 다음과 같다.
1) 입력 비디오 프레임의 정의
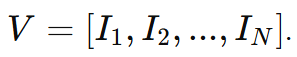
입력 비디오를 N개의 프레임으로 구성된 시퀀스로 정의한다. 이를 CLIP visual encoder를 통해 특징 벡터로 변환한다.
2) CLIP 비주얼 인코더를 통한 특징 추출
어떻게 자동차에 심을 거냐... 이걸 어떻게 검증하고 현실 세계에 반영할 것이냐..